Information Technology Reference
In-Depth Information
Fig. 1.7.
Contextual effects of letter perception. The letters in the middle of the words 'THE',
'CAT', and 'HAT' are exact copies of each other. Depending on the context they are either
interpreted as 'H' or as 'A'.
Q
Q Q
Q Q Q
Q O Q
Q
Q Q QQ QQQ Q
Q QQ QQQ OQQ
QQQ QQQ Q Q Q
Q QQ QQ Q QQQQ
Q QQ QQ QQQ
TT T TTT T TT TT
T TT T TTT T T
T O T T TT TTT
T TTT T T T TT T
TT TTT TT TTT
Fig. 1.8.
Pop-out and sequential search. The letter 'O' in the left group of 'T's is very salient
because the letters stimulate different features. It is much more difficult to find it amongst
'Q's that share similar features. Here, the search time depends on the number of distractors.
the visual system does not perceive absolute brightness, but constructs the bright-
ness of an object by filling-in its area from relative brightness percepts that have
been induced at its edges. Similar filling-in effects can be observed for color per-
ception.
Figure 1.7 shows another example of contextual effects. Here, the context of an
ambiguous letter decides whether it is interpreted as 'H' or as 'A'. The perceived let-
ter is always the one that completes a word. A similar top-down influence is known
as word-superiority effect, described first by Reicher [189]. The performance of let-
ter perception is better in words than in non-words.
The human visual system uses a high degree of parallel processing. Targets that
can be defined by a unique feature can be detected quickly, irrespective of the num-
ber of distractors. This visual 'pop-out' is illustrated in the left part of Figure 1.8.
However, if the distractors share critical features with the target, as in the middle
and the right part of the figure, search is slow and the detection time depends on
the number of distractors. This is called sequential search. It shows that the visual
system can focus its limited resources on parts of the incoming stimuli in order to
inspect them closer. This is a form of attention.
Another feature of the human visual system is active vision. We do not perceive
the world passively, but move our eyes, the head, or even the whole body in order
to to improve the image formation process. This can help to disambiguate a scene.
For example, we move the head sideways to look around an obstacle and we rotate
objects to view them from multiple angles in order to facilitate 3D reconstruction.
1.1.3 Limitations of Current Computer Vision Systems
Computer vision systems consist of two main components: image capture and in-
terpretation of the captured image. The capture part is usually not very problematic.
2D CCD image sensors with millions of pixels are available. Line cameras produce
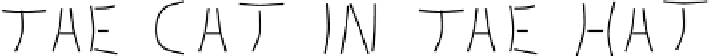


Search WWH ::

Custom Search