Database Reference
In-Depth Information
+
+
+
(a)
(b)
(c)
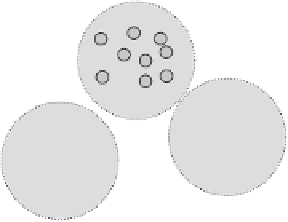
Figure 6.5 Example of clustering with different basic methods. (a)
k
-means. (b) Hierarchi-
cal. (c) Density-based.
that lies in the perfect center of the cluster
5
, then reassigns each object to the
centroid that is closest to it. Such iterative process stops when convergence
(perfect or approximate) is reached.
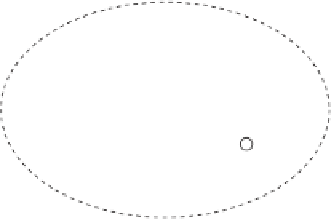
Hierarchical clustering
methods (Figure
6.5
b) try to organize objects in a
multilevel structure of clusters and subclusters. The idea is that under tight
proximity requirements, several small and
specific
clusters might be obtained,
while loosening the requirements some clusters might be merged together into
larger and more
general
ones. For instance,
agglomerative
methods start from
a set of extremely small clusters - one singleton for each input object - and
iteratively select and merge together the pairs of clusters that are most similar.
At each iteration, then, the number of clusters decreases by one unit, and the
process ends when only one huge cluster is obtained, containing all objects.
The final output will be a data structure called
dendogram
, represented as a
tree where each singleton cluster is a leaf, and each cluster is a node having as
children the two subclusters that originated it through merging.
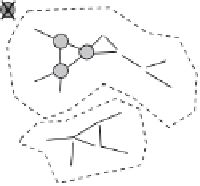
Finally,
density-based clustering
(Figure
6.5
c), as already introduced in Sec-
tion
6.2.1
, is aimed to form maximal, crowded (i.e., dense) groups of objects,
5
Notice that such object is a new one, computed from those in the cluster. Therefore, some level of
understanding of the data structure is needed here. When that is not possible, usually a variant is
applied, called
k-medoid
, that selects the most central object of the cluster as representative.