Information Technology Reference
In-Depth Information
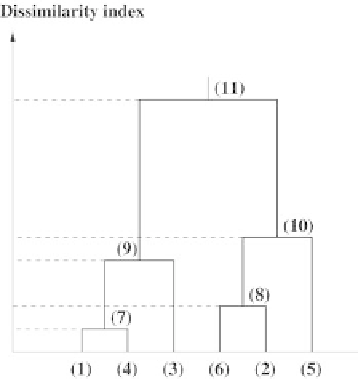
Fig. 7.19.
Clustering the neurons of the map using bottom-up hierarchical classifi-
cation: the leaves of the tree represent the neurons (here there are six neurons); for
each cluster, the vertical axis provides the clustering index for the selected similarity
4. For a given partition, find the closest subsets in the sense of the selected
similarity criterion, and cluster them together in order to get a single
subset.
5. If the number of clusters of the current partition is larger than
K
,goto
step (2), otherwise terminate the algorithm.
Several similarity measures are proposed in the literature [Jain et al. 1988].
The most popular one is due to Ward. It consists in aggregating clusters in
such a way that the sum of the cluster inertia is as small as possible. That is
a way of favoring clusters that are as compact as possible in the (Euclidean)
data space. If that criterion is selected to cluster the neurons of the map, the
working space is the data space and the associate reference vectors are the
neurons. Conversely, since the neurons are distributed on the map with its
awn discrete graph topology, one may choose to favor aggregation in a way
that takes into consideration that discrete structure. Those clusters will be
made of neurons that tend to form connected sets on the map [Murtagh 1985;
Yacoub et al. 2001]. The choice one of those two strategies, or the use of a
hybrid strategy that combines both of them, may have a crucial influence on
the results.
Hierarchical classification allows generating an arbitrary number of sub-
sets, since clustering may be stopped at any iteration. For a given similarity
measure, the number of partition elements depends on the number
S
of classes
that are sought. That number also depends on the agreement between the
unsupervised statistical partitioning and the partition into
S
classes that is
determined by the application. That number may be higher than
S
if a class
Search WWH ::

Custom Search