Information Technology Reference
In-Depth Information
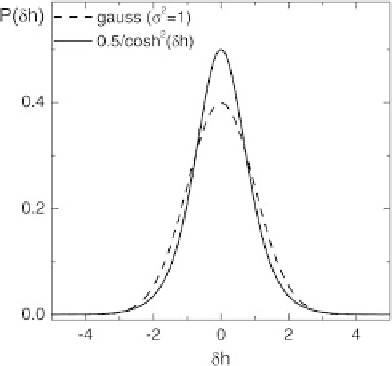
Fig. 6.20.
Comparison between a Gaussian and the noise distribution proposed in
this section
Depending on the specific expression of the noise term
p
(
δ
), the probability of
misclassification has various expressions. Assume that
p
(
δ
) has the following
bell-shaped distribution,
β
2cosh
2
(
βδ
)
,
p
(
δ
)=
which is close to a Gaussian, as may be seen on Fig. 6.20. In the latter relation,
the parameter
β
−
1 plays the same role as the variance of the Gaussian: the
larger
β
, the narrower the distribution. Replacing
p
(
δ
)into
P
γ
k
+
δ
k
<
0
,
and neglecting first order terms in
δ
, we obtain the expected training error on
example
k
,
2
1
tanh(
βγ
k
)
.
=
1
ε
t
−
This expression is nothing but the cost function of the Minimerror algo-
rithm.
Remark 1.
Within the probabilistic formulation, the cost of Minimerror is
the expected training error under additive noise on the inputs.
Remark 2.
If the noise is Gaussian
p
(
δ
)=1
/σ
√
2
π
exp(
δ
2
/
2
σ
2
) the training
error is proportional to the Error function. The latter is more di
cult to treat
numerically than the hyperbolic tangent. This justifies the above mentionned
bell shaped noise assumed for
p
(
δ
) in the training algorithms.
−

Search WWH ::

Custom Search