Information Technology Reference
In-Depth Information
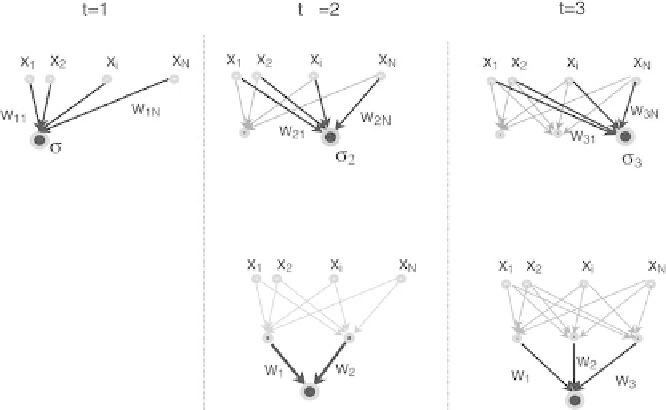
Fig. 6.19.
Schematic representation of the NetLS training algorithm
Remark 2.
The network has a single hidden layer because it has been shown
[Cybenko 1989] that, under mild conditions, a single hidden layer is su
cient
to represent any function of the inputs.
Remark 3.
The main drawback of constructive algorithms is that the result
depends critically on the separation obtained with the first hidden unit. In
some cases, keeping the neuron that makes the smallest number of errors may
not be the best strategy. Since the neurons added sequentially learn to improve
the classification quality by making the internal representations faithful, a
poor choice of the first hidden unit may have important consequences on
the classifier performance. To avoid this problem, it may be wise to begin
with different initial separations, and use the techniques of model selection
described in Chap. 2.
6.5.3 Support Vector Machines (SVM)
Support vector machines (SVMs) are generalized perceptrons with high-order
potentials. They allow finding, at least in principle, discriminant surfaces of
any shape. Recently, their applications have been extensively developed. In
this section we introduce the SVM's, and describe the principles of the learning
algorithm.
One of the assets of SVMs is the fact that their cost function is convex
(i.e., it has a single minimum), in contrast with the algorithms described
thus far. Both the least squares cost function usually used in regression or
the cross-entropy used for classification problems in Chap. 1, may have local
minima. The constructive algorithms find different solutions depending on
Search WWH ::

Custom Search