Information Technology Reference
In-Depth Information
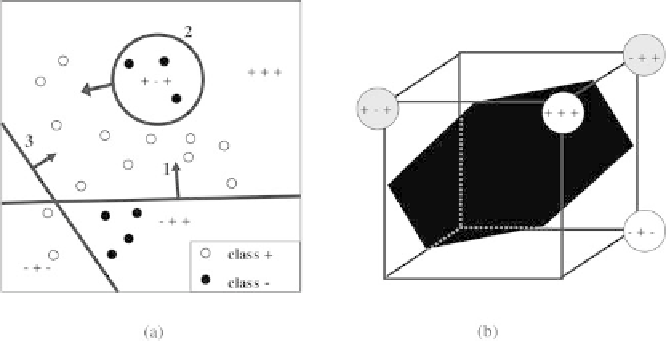
Fig. 6.18.
(
a
) Discriminant surfaces generated with the algorithm NetLS. (
b
) In-
ternal representations corresponding to the regions of figure (
a
). The surface shown
corresponds to the linear separation of the internal representations, implemented by
the output neuron
Remark.
The internal representations of the training set are said to be
faith-
ful
if the examples of different class are given different representations. Note
that different examples may have the same representation, provided they be-
long to the same class. This is even desirable, since it allows information
compression.
The different constructive or incremental algorithms in the literature generate
the internal representations through the sequential addition of hidden units.
Especially adapted to learn discrimination tasks with neural networks, they
differ by the heuristics (what has to be learnt to the successive hidden units),
the final network architecture (trees, layered, etc.) and the algorithm used
to train the individual neurons. In particular, the
number
of hidden neurons,
which determines the dimension of the internal representations, depends cru-
cially on the e
ciency of the training algorithm.
In the following we briefly describe the constructive algorithm NetLS. It
generates separations such as those shown on Fig. 6.18(a). In this example, the
first hidden neuron (numbered 1 on the figure) implements a linear separation
in input space. The second and third ones perform a spherical and a linear
separation respectively. The regions thus defined in input space are mapped
to faithful internal representations, shown on Fig. 6.18(b). Since they are
binary vectors (in dimension 3 in this case), they lie at the vertex of the
hypercube in the space of hidden neuron outputs. A separating hyperplane is
shown on the same figure. The internal representations are linearly separable:
an output perceptron connected to the hidden units can correctly implement
the discrimination. It is important to emphasize that the only way to obtain
a neural network with binary hidden units is to build it by adding binary
perceptrons sequentially.
Search WWH ::

Custom Search