Information Technology Reference
In-Depth Information
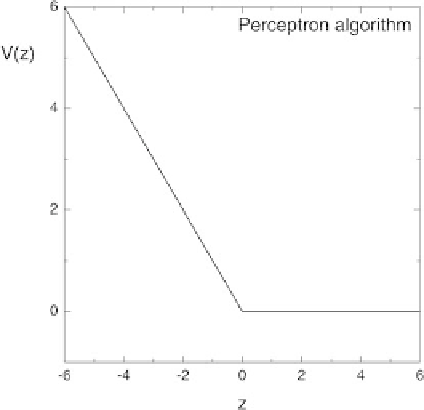
Fig. 6.11.
Partial cost corresponding to a nonadaptive (“batch”) version of the
perceptron algorithm
all correctly classified patterns from the sum), instead of considering only one
pattern at each update, as the perceptron algorithm does.
The Adaline algorithm, also called delta rule, Widrow-Hoff algorithm, or
relaxation algorithm, derives from the following partial cost:
V
(
z
)=
1
2
z
2
Θ
(
−
z
)
shown on Fig. 6.12. The weights updates at successive iterations are given by
M
∆
w
=
µ
1
M
z
k
Θ
(
−z
k
)
y
k
x
k
.
k
=1
Remark.
If a solution without training errors exists, i.e., if the training set is
linearly separable, and if the training set is equilibrated, that is, contains pos-
itive and negative examples in similar proportions, then most of the presented
algorithms may find the separating hyperplane after more or less iterations.
However, it is worth to remind that the learning rate
µ
must be small enough.
The above algorithms penalize the weights that produce training errors, since
the partial costs corresponding to negative aligned fields have positive values.
Correctly classified patterns have vanishing cost (except for Hebb's rule), in-
dependently of their position in input space. However, intuitively we are more
confident about the classification of patterns far from the separating hyper-
plane, generally surrounded by patterns of the same class, than about that of
patterns very close to it. Thus, hyperplanes too close to the patterns should
Search WWH ::

Custom Search