Information Technology Reference
In-Depth Information
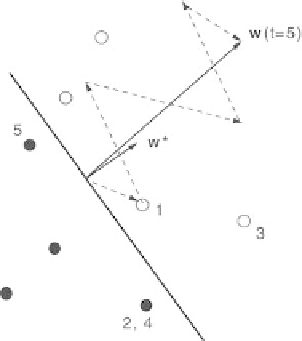
Fig. 6.7.
Vector
w
after 5 iterations of the perceptron algorithm: the examples used
for learning (
black circles
:class
−
1,
white circles
: class +1) are numbered following
the order in which they have been used. The weight vector
w
∗
is one solution. The
weight vector
w
(
t
= 5) correctly separates all the examples
2.
if z
k
≡
y
k
w
(
t
)
x
k
>
0 (the example
k
is correctly classified)
then go
·
to
learning
3.
else
(a) update the weights' components (
i
=1
,...,N
+1):
w
i
(
t
+1) =
w
i
(
t
)+
y
k
x
i
(b) increment the counter of updates:
t
=
t
+1,
(c)
go to
test
The perceptron algorithm iterates the weights modifications as long as
there are classification errors of the training patterns, that is, examples with
negative aligned fields
z
k
. Figure 6.7 presents an example of the application
of the Perceptron Algorithm in two dimensions. Clearly, if the training set
is not linearly separable, the algorithm will never stop (in contrast with the
algorithm of Ho and Kashyap presented in Chap. 1).
Remark.
The perceptron algorithm cannot determine whether a training set
is linearly separable or not, because it is not easy to distinguish in a reason-
able training time whether the algorithm entered an infinite loop because the
examples are not linearly separable, or whether the examples are separable
but convergence is slow. The algorithm of Ho and Kashyap [Ho 1965] provides
an answer to that question: if the examples are linearly separable, it obtains a
solution (which should not be expected to be optimal); if they are not linearly
separable, it signals that after a finite number of iterations.
If the examples are linearly separable, the perceptron algorithm converges, as
proved in the following theorem.
Search WWH ::

Custom Search