Information Technology Reference
In-Depth Information
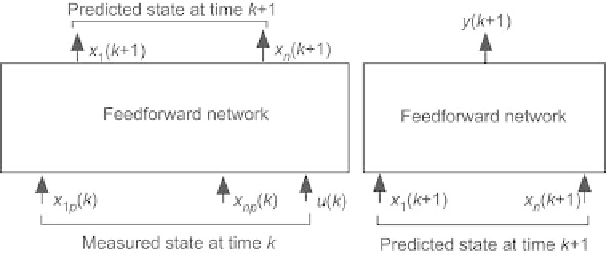
Fig. 2.46.
Copy
k
for the training of a state-space model with two different networks
for state and output prediction
Both the state predictor and the output predictor are feedforward. State
prediction can be performed either by
n
different networks, which have iden-
tical inputs, but which predict different state variables, or by a single network
that predicts all state variables,
•
The state at time
k
+ 1 is computed from the measured state at time
k
and from the control inputs at time
k
.
•
The output at time
k
+ 1 is computed from the state computed at time
k
+1.
Figure 2.46 shows the model if two different neural networks are used for
computing the state variables and for computing the output.
Because the training of those networks is directed, it is performed as the
training of a feedforward neural network.
The note related to the dumb predictor, in the section devoted to the
directed training of input-output models, is also relevant to the training of
state-space models.
Implementation of Directed and Semidirected Algorithms
All equations for the implementation of directed or semidirected algorithms
can be found in Chap. 3, pages 64 to 69 (input-output models) and 72 to 81
(state-space models), of [Oussar 1998]. A very complete technical discussion
can be found in that document.
2.7.3.5 Adaptive (On-Line) Training of Recurrent
Neural Networks
Dynamic models, just as static ones, can be trained adaptively. Adaptive
algorithms for dynamic models are described in Chap. 4, in the framework
of stochastic approximation. The same principles as those described above
for nonadaptive training apply (influence of noise on the choice of training
Search WWH ::

Custom Search