Information Technology Reference
In-Depth Information
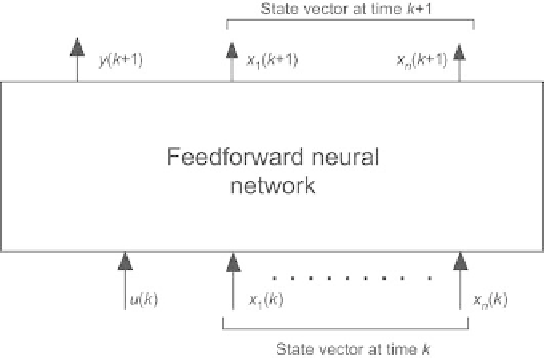
Fig. 2.45.
Copy
k
of he feedforward neural network of the canonical form, for
semidirected training of a state-space model
2.7.3.3 Nonadaptive (Batch) Training of Recurrent State-Space
Models: Semidirected Training
Just as in the case of input-output models, training requires unfolding the
model into a feedforward neural network made of
N
identical copies of the
feedforward neural network of that canonical form, whose inputs are, for
copy
k
,
•
the control input
u
(
k
),
the state vector at time
k
[
x
1
(
k
)
,...,x
n
(
k
)]
T
,
•
and whose outputs are
•
the output
y
(
k
+1),
•
the state vector at time
k
+1 [
x
1
(
k
+1)
,...,x
n
(
k
+1)]
T
.
The latter vector is part of the state inputs of the next copy, corresponding to
time
k
+1 (Fig. 2.45) The initialization of the first copy is less straightforward
than for an input-output model, since the initial state is not known. It can be
taken equal to zero, for instance.
Because the state is imposed for the first copy only, the algorithm is called
semidirected.
2.7.3.4 Nonadaptive (Batch) Training of Feedforward State-Space
Models: Directed Training
Under the state noise assumption, and if state variables are measured, the
ideal model is a feedforward model that predicts the state and the output,
either with a single network, or with two different networks.
Search WWH ::

Custom Search