Information Technology Reference
In-Depth Information
The designer must choose the input vector at time zero. If the process
output is known during the first
n
time steps, those values are natural can-
didates for being the initial values. The process output is taken into account
during the first
n
time steps only: that is why the present algorithm is called
semidirected
, as opposed to directed algorithms, whereby the process output
is input to the model at each time step.
NARMAX Assumption
Because the predictor is recurrent, its training requires, as in the previous
case, unfolding the recurrent network into a feedforward neural network,
made of
N
identical copies of the feedforward part of the canonical form.
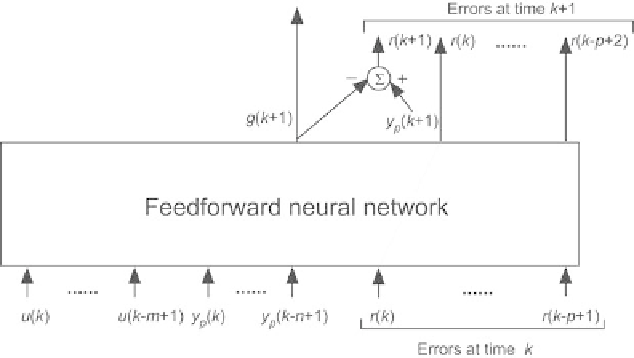
All copies have the same vector of parameters. The input of copy
k
(shown on
Fig. 2.44) is
the control input vector [
u
(
k
)
,...,u
(
k −m
+1)]
T
,
•
the vector [
y
p
(
k
)
,...,y
p
(
k −n
+1)]
T
,
•
•
the vector of errors at time
k
and at the previous
p
time steps [
r
(
k
)
,...,
r
(
k
p
+1)]
T
.
−
The output vector of copy
k
is the vector of errors at time
k
+1 and at the
previous
p
time steps [
e
(
k
+1)
,...,e
(
k
p
+2)]
T
. Therefore, the network
computes only
e
(
k
+ 1), the other components of the error vector at time
k
+1
being derived from the errors at time
k
by a unit time delay. The vector of
errors at time
k
+ 1 is part of the input vector of the next copy, corresponding
to time
k
+1.
−
Fig. 2.44.
Copy
k
of the feedforward neural network of the canonical form, for
training a NARMAX model
Search WWH ::

Custom Search