Information Technology Reference
In-Depth Information
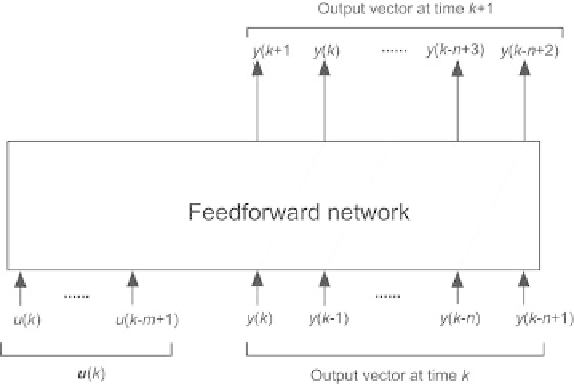
Fig. 2.43.
Copy
k
of the feedforward neural network of the canonical form, for
semidirected training
2.7.3.2 Nonadaptive (Batch) Training of Recurrent Input-Output
Models: Semidirected Training
Under the output noise assumption, or the output noise and state noise as-
sumption, the ideal model is a recurrent model, the inputs of which are
•
the control inputs and the outputs of the model at the
n
previous time
steps (under the assumption of output noise alone),
•
the control inputs, the outputs of the model and the modeling errors on a
suitable horizon
p
(under the NARMAX assumption).
Output Noise Assumption
Because the model is recurrent, its training, from a sequence of length
N
,
requires unfolding the network into a large feedforward neural network, made
of
N
identical copies of the feedforward part of the canonical form. The input
of copy
k
(shown on Fig. 2.43) is
m
+1)]
T
,
•
the control input vector
u
(
k
)=[
u
(
k
)
,...,u
(
k
−
•
the vector of outputs at time
k
and at the previous
n
time steps [
y
(
k
)
,...,
y
(
k
n
+1)]
T
.
−
The output vector of copy
k
is the vector of the outputs at time
k
+1 and at
the previous
n
time steps [
r
(
k
+1)
,...,r
(
k
n
+2)]
T
. Therefore, the network
actually computes
r
(
k
+ 1) only, the other components of the output vector
being derived from the input vector by a unit delay. The output vector of copy
k
is part of the input vector of the next copy, corresponding to time
k
+1.
−
Search WWH ::

Custom Search