Information Technology Reference
In-Depth Information
1
0.8
0.6
0.4
0.2
0
-0.2
w
= 0.1
w
= 1
w
= 10
-0.4
-0.6
-0.8
-1
-3
-2
-1
0
1
2
3
x
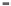
Fig. 2.13.
Function
y
= tanh(
wx
) for 3 values of
w
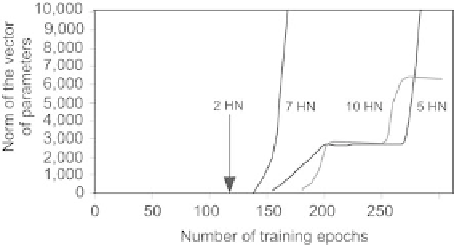
Fig. 2.14.
Norm of the vector of parameters during training
where
q
is the number of parameters of the classifier, and
α
is a hyperpara-
meter whose value must be found by performing a tradeoff: if
α
is too large,
the minimization decreases the values of the parameters irrespective of the
modeling error; by contrast, if
α
is too small, the regularization term has no
impact on training, hence overfitting may occur.
The operation of the method is very simple: the gradient of
J
is com-
puted by backpropagation, and the contribution of the regularization term is
subsequently added,
J
∗
=
∇
∇
J
+
α
w
.
Nevertheless, it should be noticed that the parameters of the network have
different effects:







































Search WWH ::

Custom Search