Image Processing Reference
In-Depth Information
Figure 4.12:
Local deformation models. The surface mesh is divided into overlapping patches, whose
deformations are modeled either as linear combinations of modes or in terms of a GPLVM. This can be
used to represent surfaces of arbitrary shape or topology by adequately assembling local patches.
where
L
is the diagonal matrix containing the inverse eigenvalues associated with the eigenvectors
in
S
. As in the global case, this regularizer could be written as a linear system, and added as a penalty
term to the correspondence equations of Eq.
4.1
. Unfortunately, without additional constraints,
linear local models suffer from the same shortcomings as global ones: Some of the singular values of
the matrix of the resulting linear system remain small and additional knowledge must be introduced.
As a consequence, in
Salzmann and Fua
[
2011
], the shape regularization term of Eq.
4.14
was
used in conjunction with the geodesic distance preservation constraints introduced in Section
4.2.3
.
An iterative scheme where each correspondence equation is re-weighted according to the current
reprojection error allow the algorithm of
Salzmann and Fua
[
2011
] to tolerate up to 30% of erro-
neous correspondences between the reference and input image. This is enough in many practical
applications, but may not suffice in truly difficult situations, such as when the texture is highly
repetitive, as shown in Fig.
4.13
. Reliable correspondences then become very difficult to establish
because, based on image appearance alone, a 2D interest point in the reference image could match
equally well any number of points in the input image. In
Shaji
et al.
[
2010
], the problem is recast
as one of simultaneously solving for shape and correspondences, which makes it possible to use
geometrical consistency constraints when establishing the correspondences. As a result, when faced
with a repetitive pattern such as the one of Fig.
4.13
, it yields more reliable correspondences and, as
a consequence, a better 3D shape. The approach starts with the formulation of
Salzmann and Fua
[
2011
] and extends it by allowing one point in the reference image to potentially correspond to more

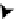



Search WWH ::

Custom Search