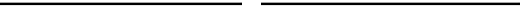Database Reference
In-Depth Information
Table 4.2 Illustration of the simulation
Real
Correct forecast
Step TA
REs Views Baskets Buys Rev.
Views Baskets Buys
Rev.
1
A
C, B 1
0
0
0
0
0
0
0
2
D
E, A 2
0
0
0
0
0
0
0
3
D basket
2
1
0
0
0
0
0
0
4
A
C, E 3
1
0
0
1
0
0
0
5
A basket
3
2
0
0
1
1
0
0
6
A bought
3
2
1
35.00
1
1
1
35.00
Quality of forecast
33 % 50 %
100 % 100 %
one and attains the value 2. Since D is none of the previous recommendations, the
counter of views correctly predicted by the RE remains at 0. In step 3, the product D
is added to basket; the basket counter is increased.
In step 4, another view of A takes place; this time, this coincides with the second
recommendation issued by the RE, and hence, its view counter is now also increased by
one. Since, in step 5, the correctly predicted product has been added to basket, the RE's
basket counter also increases by one. In the last step 6, only the product recommended
by the RE is eventually bought. Therefore, the buy counter increases by one and
the forecasted revenue by the price of the purchased product (here, 35 EUR). By and
large, the RE has correctly predicted 33%of the actual views, 50%of the products that
have actually been added to basket, and 100 % of the purchased products.
Please mind that in step 4, the RE issues recommendations that differ from those
for the same product in step 1 (namely, C and E instead of C and B). This is because
the RE learns dynamically. As a result of this dynamic, the measurements obtained
in simulation mode differ slightly from those obtained in online mode. Neverthe-
less, the order of magnitude is the same, and with an increasing number of trans-
actions, the measurements assimilate toward each other.
Besides the above-described online procedure for assessing the quality of fore-
cast, we also occasionally deploy offline validation procedures. Here, we subdivide
the transaction data into a training set and a test set, which are, respectively, drawn
from transaction logs of different days, for example, the file of April 18th for
training and that of April 19th for testing. Sometimes, however, we also carry out
the training-test decomposition within the same session, which is, e.g., accom-
plished by using all but the last
n
transactions of each session for training and the
remaining ones for testing.
We now learn the recommendation model from the training set, as in the online
test, and apply it to forecasting on the test set. The qualities of forecasts are
computed with respect to the same characteristic figures for views, adds to basket,
purchases, and revenue. In terms of the terminology commonly used in the area of
verification of recommendation algorithms [SKKR00], we measure the
precision
(what we have used so far). We abstain from using the
recall,
another popular
measure, which describes the coverage ratio of the test set by recommendations.
To avoid overloading the already fairly complex testing procedures, we also refrain
from further measures.