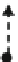Database Reference
In-Depth Information
a
b
c
d
a
198
167
138
-393
1
s
3
a
188
173
169
93
0
a
194
168
145
-271
1
s
2
176
a
167
165
127
0
a
182
172
170
155
1
s
1
a
176
168
167
157
0
a
ss
a
ss
a
ss
a
ss
r
3
=
100
r
3
=
80
r
3
=
50
r
=
−
500
3
Fig. 3.5 Example of the car. Action values and optimal policies (
bold arrows
) for different
r
ss
3
values of the third state. The larger the dot for a state, the higher its state value
Improvement
π
→
greedy
(
q
)
q
π
q
→
q
Evaluation
q*
Fig. 3.6 GPI. Policy and action-value functions interact until they are mutually consistent
and thus optimal
the transition into the last state. As
r
ss
3
reduces, the number of states with
non-acceleration actions increases. In the last case d),
r
ss
3
¼
500 finally becomes
so small that even in the first state, the optimal action is not to accelerate, although the
reward of the second state is higher than that of the first one. However, the transition
into the unattractive last state is so dangerous that, although we did not accelerate in
the second state, even the tiny probability of a transition into the last state is still too
high! Thus, our example of the car is a very good illustration of chain optimization.
■