Java Reference
In-Depth Information
Note
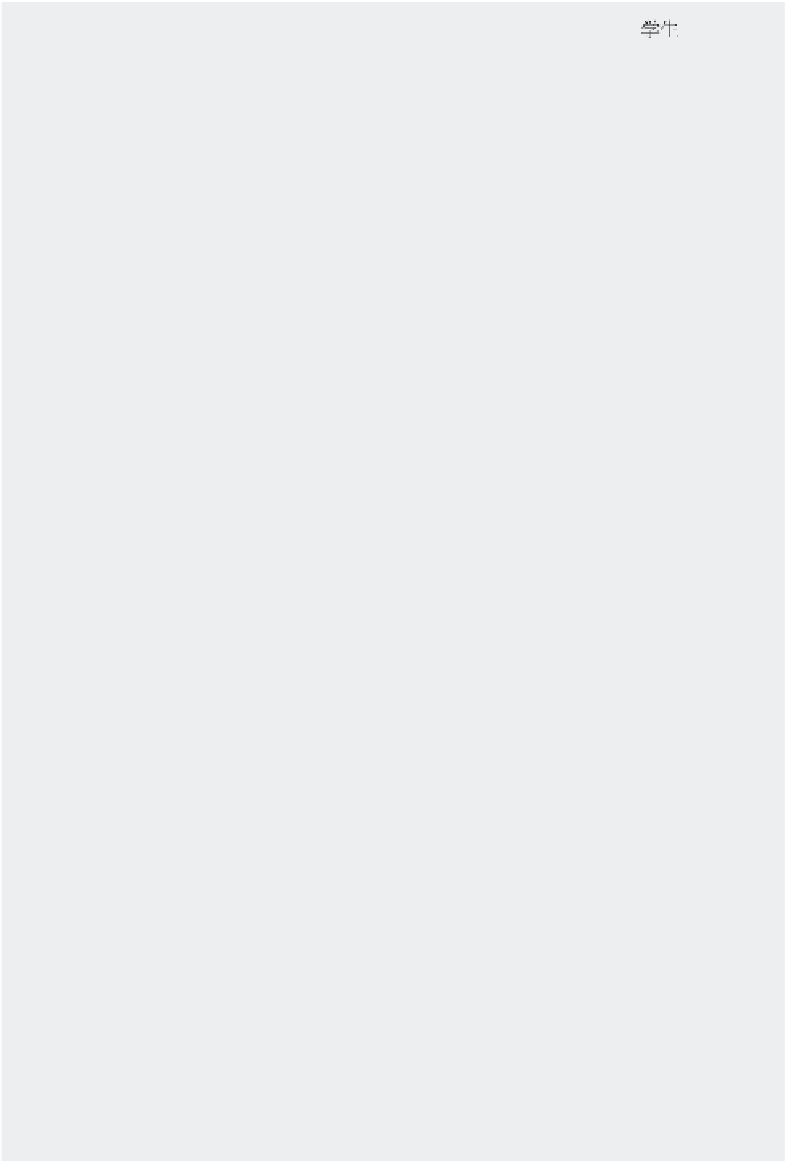
By the way, you might have tried to create a class nam
ed “ ” in
Eclipse, only to have it show up as an empty file with Eclipse throwing a warn-
ing about character encodings. The reason for this is that Eclipse by default
uses a subset of all possible characters for source code, called
Cp1252
. While
this subset contains most Western characters, it does not contain Chinese,
Japanese, Thai, or other characters found in non‐Western languages. This
implies that it is also not possible to include code such as this:
System.out.println("The word for student in " +
"Chinese and Japanese is written in the " +
"same way:
");
If you want to use all characters in Eclipse source code, you will need to
open the Preferences window, navigate to General Workspace, and then
select Other: UTF‐8 under Text File Encoding. This will ensure that Eclipse
saves your source files with Unicode encoding, and will thus allow you to use
Unicode class names and output. (Unicode is a gigantic character set support-
ing and containing almost all character glyphs in use by humanity today; see
www.unicode.org
fo
r more details.)
Before you rush off to the preferences to change this setting, keep in mind,
however, that changing the source file encoding is generally a bad idea. The
reason for this mainly stems from portability and compatibility. Not all oper-
ating systems and Java versions support Unicode equally well, meaning that
Unicode characters that look and open fine on your workstation (with your ver-
sion of Eclipse) might not show up correctly on other people's machines.
But what if you just came up with a killer application and want to target the
Chinese market? Surely, it should be possible to translate your program? When
that happens, you have two ways to make this work. The first is to change your
source file encoding (and deal with portability issues as they pop up). The sec-
ond way is to use “escape” Unicode characters, like so:
System.out.println("The word for student in " +
"Chinese and Japanese is written in the " +
"same way: \u5B66\u751F");
To escape a Unicode character, you write a backslash (
\
), followed by the low-
ercase letter
u
, followed by four hexadecimal (0‐9, A‐F) characters represent-
ing the code point of the character. You can find tables and websites helping
out with this task online. One such example that allows you to look up charac-
As a final note, you might have tried one of these code samples in Eclipse to
see if the text appears in the output, only to see two question marks (
??
) or
garbled text appearing where the Unicode characters should be. The reason
behind this is that not only does your editor need to enable support for saving
Unicode files, your console—which runs the program—must also be able to
continues


Search WWH ::

Custom Search