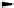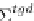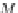Database Reference
In-Depth Information
Fig. 4.2
Query answering
process
(q)
over the retrieved global database is equal to the answer to
q
over the
canonical database.
2. In order to avoid the building of the retrieved global database, the query does
not evaluate
exp
exp
G
(q)
over the retrieved global database. Instead, this algorithm
G
unfolds
exp
(q)
to a new query, called
unf
(exp
(q))
, over the source relations
G
M
G
on the basis of
M
, and then uses the unfolded query
unf
(exp
(q))
to access
M
G
the sources.
Figure
4.2
shows the basic idea of this approach (taken from [
2
]). In order to obtain
the
certain answers
, the user lifted query
q
could in principle be evaluated
(dashed arrow) over the (possibly infinite) canonical database
can(
q
I
I
,D)
, which is
generated from the retrieved global database
ret(
,D)
can be
obtained from the source database
D
by evaluating the queries of the mapping. This
query answering process instead expands the query according to the constraints
Σ
tgd
G
I
,D)
. In turn,
ret(
I
in
, and then evaluates it on the source database.
The architecture of such a query-rewriting GAV system [
3
], based on the
Database Federation tool for DB2 (IBM), is presented in Fig.
4.3
.
Let us show how the symbolic diagram in Fig.
4.2
can be effectively represented
by the commutative diagrams in
DB
, corresponding to the homomorphisms be-
tween T-coalgebras that represent the equivalent queries over these three instance-
databases: each query in the
DB
category is represented by an arrow and
can be
composed
with the arrows that semantically denote mappings and integrity con-
straints.
G
, than unfolds it according to
M
Theorem 8
be a GAV data integration system with a canonical
model provided by an R-algebra functor α
∗
:
Let
I
=
G
,
S
,
M
Sch
(
I
)
−→
DB
(
Corollary
15
),
with
the source database α
∗
(
S
)
=
D
,
the retrieved global database α(
G
T
)
=
ret(
I
,D)
for
I
w
.
r
.
t
.
D
,
and the universal
(
canonical
)
database α(
G
)
=
can(
I
,D) for
I
w
.
r
.
t
.
D
.