Information Technology Reference
In-Depth Information
The above observations represent the principle of the exact method to compute
exponents of growth based solely on the cells' structure. The method will be de-
tailed in the next.
7.4.2 Minimal Set of Cells to Compute the Probabilistic Exponent of
Growth
In order to specify the values of
n
(number of uncertain cells in the initial state)
and
N
(minimum number of cells in the set needed to compute the probabilistic
exponent of growth properly) one should take in consideration the neighborhood
connectivity. It should also consider that as long as all inputs to a cell are certain
(1 or 0) the output is certain too. Therefore there will be no need for more than
N
cells in the CA, as long as the cases when cells will receive “certain” inputs have
no relevance for computing the exponent of growth.
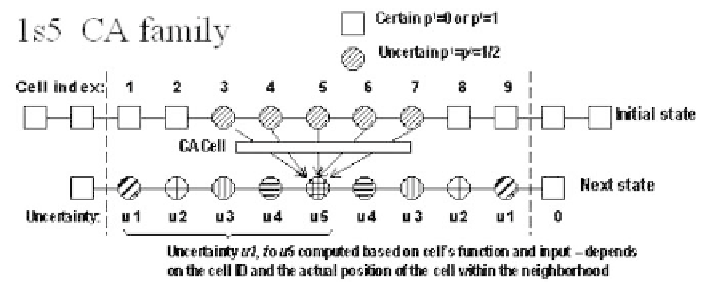
Figure 7.5 shows clearly that in the case of the
1s5
type CA,
n =
5 and
N =
2
n -
1
,
i.e.
N =
9. The
expanded area
in this case is formed of cells
k =
1, 2, 8
and 9 while the
active area
is formed by the five cells in the middle i.e.
k =
3-7.
In general, for any CA, the active area will be formed by the cells within the CA
neighborhood while the
expansion area
is formed by all cells in the neighborhood
of the
active area
such that in the next state there will be at least one uncertain in-
put from a cell within the neighborhood. Once a cell receives only certain inputs,
it is not relevant for computing the exponent of growth since it will provide a cer-
tain output (
P
0
).
Fig. 7.5.
Minimal set of CA cells involved in computing the probabilistic growth index, for
the case of
1s5
CA family. In this case there are
N
= 9 cells and the probabilistic exponent
of growth is fully determined by the cell ID, the prescribed initial state uncertainty profile
(
upper row
in the figure) and the “next state” uncertainty profile (
lower row
in the figure)
Search WWH ::

Custom Search