Database Reference
In-Depth Information
Hive Query Language (HQL)
ODBC
JDBC
Hive Web
Interface (HWI)
Command Line
Interface (CLI)
MetaStore
Thrift Server
Compiler, Optimizer, Executor
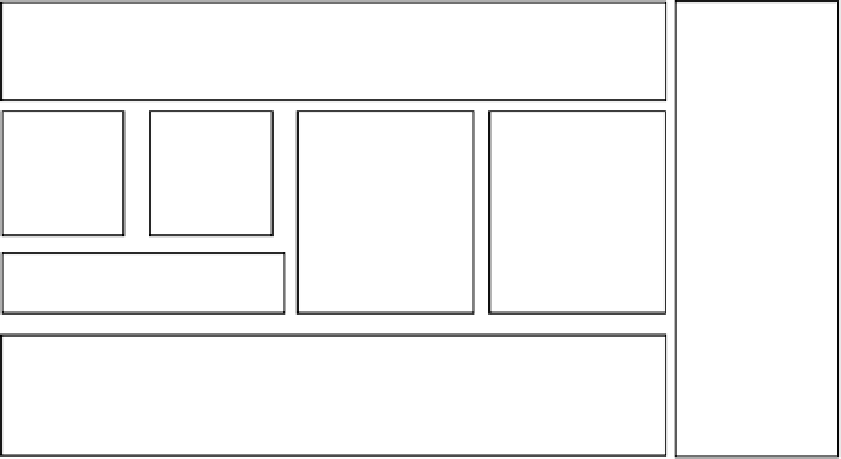
Figure 8-2.
Hive architecture
In effect, Hive enables you to create an interface layer over MapReduce that can be used in a similar fashion to
a traditional relational database. This layer enables business users to use familiar tools like Excel and SQL Server
Reporting Services to consume data from HDInsight as they would from a database system such as SQL Server,
remotely through an ODBC connection. The rest of this chapter walks you through different Hive operations and
using the Hive ODBC driver to consume the data.
Working with Hive
Hive uses tables to impose schema on data and provides a query interface for client applications. The key difference
between Hive tables and those in traditional database systems, such as SQL Server, is that Hive adopts a
schema on
read
approach. This approach enables you to be flexible about the specific columns and data types that you want
to project on top of your data. You can create multiple tables with different schema from the same underlying data,
depending on how you want to use that data. The most important point to take away from this approach is that the
table is simply a metadata schema that is imposed on data in underlying files.
Creating Hive Tables
You create tables by using the HiveQL
CREATE TABLE
statement, which in its simplest form looks similar to the
analogous statement in Transact-SQL.
One thing to note about Hive tables is that you can create two types of tables:
External
and
Internal
. If you do not
specify a table type, a table is created as
Internal
.
Be careful! An internal table tells Hive to manage the data by itself. If you drop the table, by default the data is
also dropped and cannot be recovered. If you want to manage the data and data locations, if your data is used outside
Hive, or if you need to retain the data, create an external table. The syntax is pretty much similar, requiring just the
addition of the
EXTERNAL
keyword.
You can use the
PARTITIONED BY
clause to create a subfolder for each distinct value in a specified column (for example,
to store a file of daily data for each date in a separate folder). Partitioning can improve query performance because
HDInsight will scan only relevant partitions in a filtered query.