Information Technology Reference
In-Depth Information
f
f
(
x
i
)
(
x
i
)
i
x
i
x
i
0
0.200
3.112
11.147
0.011
6
10.811
1
0.211
2.990
0.011
5
2
0.222
2.874
10.490
0.010
10.182
3
0.232
2.766
0.010
4
4
0.243
2.664
9.888
0.010
3
9.606
5
0.253
2.568
0.010
6
0.262
2.477
9.335
0.009
2
9.075
7
0.271
2.391
0.009
1
8
0.281
2.309
8.825
0.009
x
8.585
9
0.289
2.233
0.009
0
0
1
2
3
4
10
0.298
2.160
Abbildung 5.21: Gradientenabstieg mit Startwert 0.2 und Lernrate 0.001.
f
f
(
x
i
)
(
x
i
)
i
x
i
x
i
0.875
0
1.500
2.719
3.500
6
1
0.625
0.655
1.431
0.358
5
0.639
2
0.983
0.955
2.554
3
0.344
1.801
7.157
1.789
4
4
2.134
4.127
0.567
0.142
3
0.345
5
1.992
3.989
1.380
6
1.647
3.203
3.063
0.766
2
Startpunkt
0.438
7
0.881
0.734
1.753
1
8
0.443
1.211
4.851
1.213
x
0.757
9
1.656
3.231
3.029
0
0
1
2
3
4
10
0.898
0.766
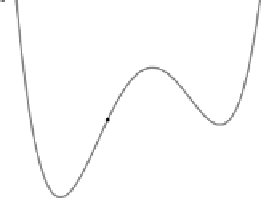
Abbildung 5.22: Gradientenabstieg mit Startwert 1.5 und Lernrate 0.25.
Problem hängt offenbar mit dem gewählten Startwert zusammen und kann daher
nicht durch eine Änderung der Lernrate behoben werden.
Für eine Veranschaulichung der Fehlerrückpropagation verweisen wir hier auf
die Visualisierungsprogramme
wmlp
(für Microsoft Windows
TM
)und
xmlp
(für Li-
nux), die unter
http://www.computational-intelligence.eu
zur Verfügung stehen. Mit diesen Programmen kann ein dreischichtiges Perzeptron
so trainiert werden, dass es die Biimplikation, das exklusive Oder oder eine von
zwei verschiedenen reellwertigen Funktionen berechnet. Nach einem jedem Trai-
ningsschritt werden die Berechnungen des neuronalen Netzes visualisiert, indem
die aktuelle Lage der Trenngeraden bzw. die Verläufe der Ausgaben der Neuronen
gezeichnet werden. So kann zwar nicht der Abstieg auf der Fehlerfunktion verfolgt
werden (was wegen der zu großen Zahl an Parametern prinzipiell unmöglich ist),
aber man erhält eine recht gute Vorstellung vom Ablauf des Trainings. Eine ausführ-
liche Erläuterung der Programme findet man auf der angegebenen WWW-Seite.