Information Technology Reference
In-Depth Information
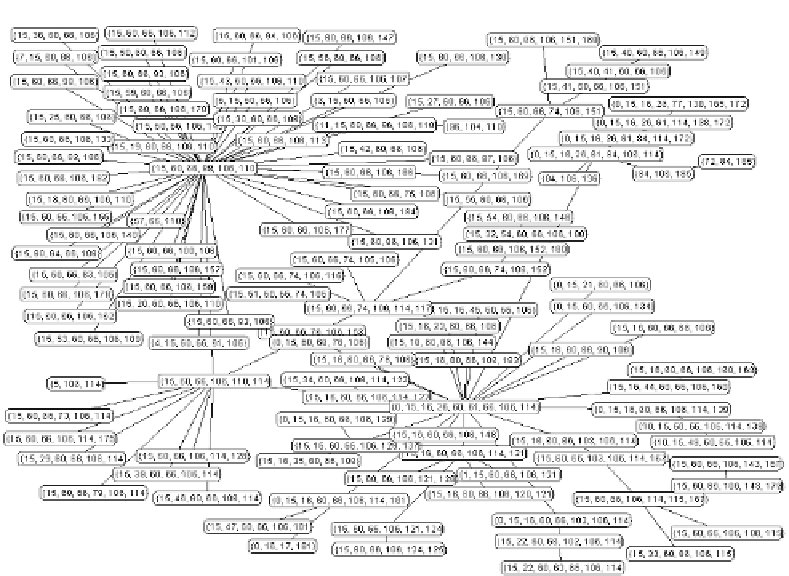
Abbildung 24.4: Markov-Netz aus einer realen Anwendung mit 186 Attributen. Die
Ve r t e i l ung konn t e du r c h 1 7 4 ma x ima l 9 - d imens i ona l e C l i quen app r ox imi e r t we rden .
Die Parameteranzahl für
p
o
rig
übersteigt jedes vorstellbare Maß, wohingegen
p
n
et
bei einer 32-Bit-Fließkommadarstellung pro Parameter bequem in 2GB Arbeitsspei-
cher unterzubringen ist:
(
4Byte
·
174
·
5
9
)
/1024
3
1.27GByte.
Es muss fairerweise angemerkt werden, dass die Verteilung
p
o
rig
in der realen
Anwendung extrem dünn besetzt sein würde: Selbst wenn jeder Mensch auf diesem
Planeten einen Volkswagen besäße, der noch dazu von der Ausstattungskombinati-
on her einzigartig wäre, dann würde die Verteilung
p
o
rig
lediglich ca. 7 Milliarden
von Null verschiedene Einträge besitzen, was im Gegensatz zu den 10
130
insgesamt
möglichen verschwindend gering wäre. Folglich würde man zur Speicherung eine
Datenstruktur nutzen, die diesem Umstand Rechnung trüge, was letztendlich auf
eine Art Auflistung der vorhandenen Fahrzeuge hinausliefe, einer Datenstruktur al-
so, die mit der Anzahl der Datensätze wächst. Die Repräsentation als Markov-Netz
kann hingegen sämtliche Fahrzeugkombinationen, deren Attribut(un)abhängigkei-
ten mit dem Markov-Netz kompatibel sind, aufnehmen, ohne dass es ein Anwach-
sen der Datenstruktur zur Folge hätte. Die Einschränkung, dass neue Daten (also
neue, in die Netzparameter einzupflegende Ausstattungshäufigkeiten) die (beding-
ten) Unabhängigkeiten erfüllen müssen, versteht sich von selbst, denn sie sind es
ja gerade, die eine effiziente Zerlegung ermöglichen. In der Praxis ist die strenge
Zerlegbarkeit (wie in Definitionen 24.7 und 24.8 gefordert) fast nie gegeben. Hier
begnügt man sich mit einer annähernden Zerlegbarkeit, wie wir sie in Kapitel 26
beim Lernen von graphischenModellen kennenlernen. Für Details zumVolkswagen-