Information Technology Reference
In-Depth Information
(1, 0)
1
1
1
y
1
1
1
0
0.
36
0
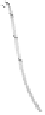
Basisfunktion (0,0)
Basisfunktion (1,1)
Ausgabe
Abbildung 6.14: Radiale Basisfunktionen und Ausgabe eines Radiale-
Basisfunktionen-Netzes mit zwei versteckten Neuronen für die Biimplikation.
können wir die Gewich-
Aus dieser Matrix und demAusgabevektor
o
u
=(
1, 0, 0, 1
)
te berechnen. Wir erhalten
w
1
w
2
0.3620
1.3375
1.3375
=
A
+
·
w
u
=
o
u
.
Die Berechnungen des so initialisierten Netzes sind in Abbildung 6.14 veranschau-
licht. Das linke und das mittlere Diagramm zeigen die beiden radialen Basisfunk-
tionen, das rechte Diagramm die Ausgabe des Netzes. Man beachte den Biaswert
und dass (etwas überraschend) genau die gewünschten Ausgaben erzeugt werden.
Letzteres ist in der Praxis meist nicht so, da ja das zu lösende Gleichungssystem über-
bestimmt ist. Man wird also i.A. nur eine Näherung erzielen können. Da hier jedoch
aus Symmetriegründen das Gleichungssystem nicht echt überbestimmt ist (aus der
Matrix
A
und dem Ausgabevektor
o
u
liest man ab, dass die zweite und die dritte
Gleichung identisch sind), erhält man trotzdem eine exakte Lösung.
Bisher haben wir die Zentren der radialen Basisfunktionen (zufällig) aus den
Tra iningsbe i spi e l en gewähl t . Besser wäre es j edoch, wenn man gee igne te Zent ren
mit einem anderen Verfahren bestimmen könnte, denn bei einer zufälligen Auswahl
ist nicht sichergestellt, dass die Zentren die Trainingsbeispiele hinreichend gut ab-
decken. Um geeignete Zentren zu finden, kommt im Prinzip jedes prototypenbasier-
te Clusteringverfahren in Frage. Zu diesen gehört z. B. die lernende Vektorquantisie-
rung, die wir im folgenden Kapitel besprechen werden. Hier betrachten wir stattdes-
sen ein Verfahren der klassischen Statistik, das unter demNamen
c
-Means-Clustering
(auch:
k
-Means-Clustering) bekannt ist [Hartigan u. Wong 1979]. Der Buchstabe
c
(bzw.
k
) im Namen dieses Verfahrens steht für einen Parameter, nämlich die Zahl
der zu findenden Cluster.
Dieses Verfahren ist sehr einfach. Zunächst werden zufällig
c
Clusterzentren,
meist aus den Trainingsbeispielen, gewählt. Dann unterteilt man die Trainingsbei-
spiele in
c
Gruppen (Cluster), indemman jedem Clusterzentrum all die Trainingsbei-
spiele zuordnet, die ihm amnächsten liegen, d. h., näher an ihm als an einem anderen
Clusterzentrum. In einem zweiten Schritt werden neue Clusterzentren berechnet, in-
dem man die „Schwerpunkte“ der gebildeten Gruppen von Trainingsbeispielen be-
stimmt. D. h., man bildet die Vektorsumme der Trainingsbeispiele einer Gruppe und
teilt durch die Anzahl dieser Trainingsbeispiele. Das Ergebnis ist das neue Zentrum.