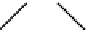Database Reference
In-Depth Information
europe
europe
europe
country
country
country
ruler
(
x
)
ruler
(
x
)
ruler
(
y
)
ruler
(
x
)
ruler
(
x
)
Figure 11.1 Examples of tree patterns
ruled in two different countries; the dashed arrow denotes the following sibling relation
between two
country
nodes.
Definition 11.1 (Pattern syntax) Tree patterns are given by the following grammar:
π
:=
(
x
)[
λ
]
|
(
x
)
(patterns)
λ
:=
μ
|
//
π
|
λ
,
λ
(sets)
+
μ
:=
π
|
π
→
μ
|
π
→
μ
(sequences)
We write
π
(
x
) to indicate that
x
is the list of all the variables used in
π
.By
π
we denote
the size of
π
, i.e., the length of its syntactic representation.
The intuition behind this syntax is as follows:
•
a pattern is either
(
x
), describing a node labeled
with attributes
x
,oritis
(
x
)[
λ
],
describing a node and part of the subtree rooted at this node (given by
λ
);
•
sets
rooted one level down (e.g., like the
ruler
→
ruler
sequence below the
country
node in the leftmost pattern in
Figure
11.1
), or single patterns which are rooted an arbitrary nonzero number of levels down
(
//
λ
have as their elements either sequences
μ
π
);
•
sequences describe patterns rooted at the same level and connections between them:
those could be next-sibling (
+
) connections.
→
) or following-sibling (
→
Before giving the formal semantics, we show how the patterns from
Figure 11.1
can now
be written in this syntax:
π
1
(
x
,
y
)=
europe
[
country
[
ruler
(
x
)
→
ruler
(
y
)]]
,
π
2
(
x
)=
europe
[
//
ruler
(
x
)]
,
π
3
(
x
)=
europe
[
country
[
ruler
(
x
)]
+
country
[
ruler
(
x
)]]
.
→
We shall use abbreviations:
(
x
)
/
π
for
(
x
)[
π
],and
]
to write patterns more compactly. For instance, the patterns above can be briefly written as
(
x
)
//
π
for
(
x
)[
//
π
π
1
(
x
,
y
)=
europe
/
country
[
ruler
(
x
)
→
ruler
(
y
)]
,
π
2
(
x
)=
europe
//
ruler
(
x
)
,
π
3
(
x
)=
europe
[
country
/
ruler
(
x
)
+
country
/
ruler
(
x
)]
.
→