Database Reference
In-Depth Information
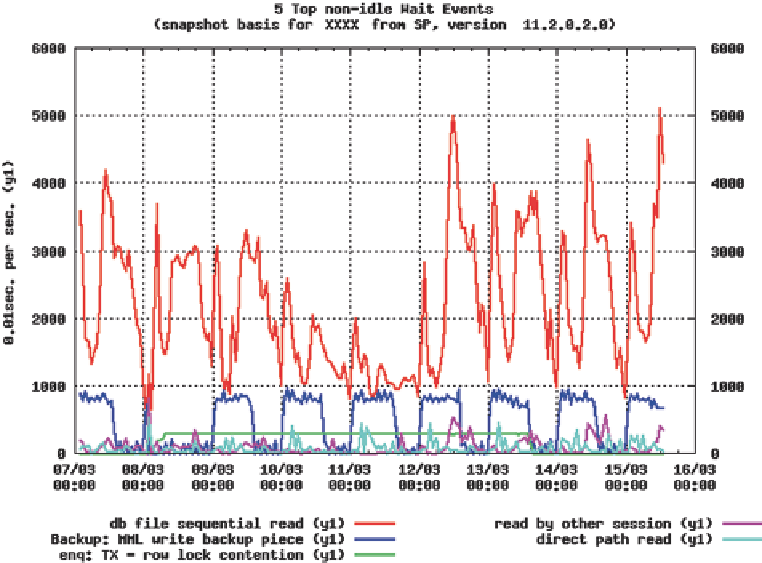
Abb. 12.6
Wartestatistiken einer Datenbank
L.: „
OK, versuchen wir gemeinsam, noch ein paar Details zu entdecken. Hast Du bemerkt,
dass die CPU-Auslastung am 10. und am 11.03. etwas kleiner war als sonst?
“
P.: „
Denkst Du, es war ein Wochenende?
“
L.: „
Ja, ich vermute das. Trotz der niedrigen CPU-Auslastung sind die Load-Werte ziem-
lich groß. Was sagt es uns?
“
P.: „
Ich weiß es nicht.
“
L.: „
Das lässt vermuten, dass dieses System viele CPUs hat. Die Anzahl der Prozesse, die
zugleich auf ‚db file sequential read' warteten, war sehr groß und betrug 50 zu den Spitzen-
zeiten. Dieses System hat entweder permanent sehr starke Performanz-Probleme oder hat
einfach sehr viele Prozesse, ein Teil davon wartet auf das I/O.
“
P.: „
Wie kommst Du auf die 50 Prozesse?
“
L.: „
Die Wartezeit für ‚db file sequential read' betrug 50 Sekunden pro 1 Sekunde. Des-
wegen kann man schätzen, dass ca. 50 Prozesse zugleich warteten.
Man sieht auch, dass das
Backup sehr lange dauert. Ich vermute, dass diese Datenbank sehr groß ist.
“
P.: „
Oder das Backup sehr langsam.
“
L.: „
Das wäre möglich, aber die anderen Statistiken deuten auch auf eine große Datenbank
mit vielen Prozessen hin. Die Wartezeiten am 10. und am 11.03. waren (wie die CPU-Aus-
lastung) kleiner als sonst. Dieses System ist wesentlich weniger an den Wochenenden belastet.
Und noch das letzte Detail: 3 Prozesse haben ca. 6 Tage lang permanent auf das Enqueue
‚
enq: TX - row lock contention
'
gewartet.
“