Database Reference
In-Depth Information
The ETL process can be tuned in many other ways as well, but we think you will find implementing these
suggestions a good start. In short, consider these points when tuning ETL performance:
•
Only select data that you need from the source; never select all columns and rows from a
table if you do not need them.
•
Use incremental loading instead of flush and fill techniques for large amounts of data.
•
Place indexes on any column that represent a foreign key in a table, since these are the
columns that will be queried when tables are joined in a SQL
SELECT
statement.
Use SQL statements to perform transformations whenever you can.
•
•
Drop indexes before filling the data warehouse with data.
•
Use RAID for all but the smallest BI solutions.
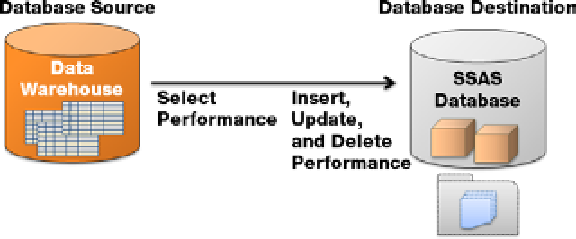
Processing Performance
The same recommendations given for the database source in the ETL operations now applies to processing the
cubes and dimensions: add more RAM, use RAID, and take only the data that you need (Figure
18-7
).
Figure 18-7.
Actions performed during cube and dimension processing
Filter Data in SSAS
You can use named queries in the data source views of your SSAS projects to restrict the data used in processing
(Figure
18-8
). This can greatly reduce processing times by selecting only the columns and rows that are needed
for a particular dimension or cube.