Information Technology Reference
In-Depth Information
1
0
1
0
1
x
1
a
x
2
a
x
3
a
x
4
a
x
5
a
x
6
0
,
1
0
,
1
0
,
1
0
,
1
0
,
1
0
1
0
1
0
x
1
b
x
2
b
x
3
b
x
4
b
x
5
b
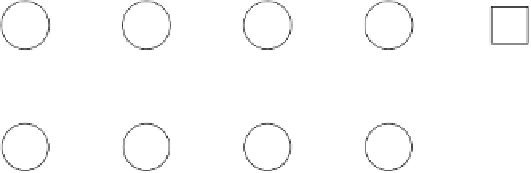
Fig. 9.2.
A 5-step corridor finite state world. The circles represent the states of the
problem, and the arrows the possible state transitions. The numbers next to the arrows
are the actions that cause the transitions, showing that the only available actions are
0 and 1. The state
x
1
a
is the initial state in which the task starts, and the square state
x
6
is the terminal state in which the task ends.
steps. In RL terms, this aim is described by giving a reward of 1 upon reaching
the terminal state, and a reward of 0 for all other transitions
4
.Theoptimal
policy is to alternately choose actions 0 and 1, starting with action 1 in state
x
1
a
.
The optimal value function
V
∗
over the number of steps to the terminal state
is for a 15-step corridor finite state world shown in Fig. 9.3(a). As can be seen,
the difference of the values of
V
∗
between two adjacent states decreases with the
distance from the terminal state.
Recall that, as described in Sect. 7.1.1, XCS seeks for classifiers that feature
the mean absolute error
0
,where
0
is the same for all classifiers. Thus, with
increasing
0
, XCS will start generalising over states that are further away from
the terminal state, as due to their similar value they can be modelled by a single
classifier while keeping its approximation error below
0
. On the other hand,
0
cannot be set too small, as otherwise the non-stationarity of the function to
model would make all classifiers seem inaccurate. Generalising over states
x
ia
for different
i
's, however, causes the policy in these areas to be sub-optimal, as
choosing the same action in two subsequent steps in the corridor finite state
world causes at least one sidestep to one of the
x
ib
states
5
.
To summarise, XCS struggles in learning the optimal policy for tasks where
the difference in value function between two successive states is very small and
might be modelled by the same classifier, and where choosing the same action
for both states leads to a sub-optimal policy. The problem was identified by
Barry [11, 12], and demonstrated by means of different-length corridor finite
state worlds in. Due to the same classifier accuracy criterion, XCSF can be
4
More precisely, the reward 1 that is received upon reaching the terminal state was
modelled by adding a transition that, independent of the chosen action, leads from
the terminal state to an absorbing state and is rewarded by 1. Each transition from
the absorbing state leads to itself, with a reward of 0.
5
It should be noted that while the classifiers in standard implementations of XCS(F)
can match several states, they always match and thus promote a single action.


















Search WWH ::

Custom Search