Database Reference
In-Depth Information
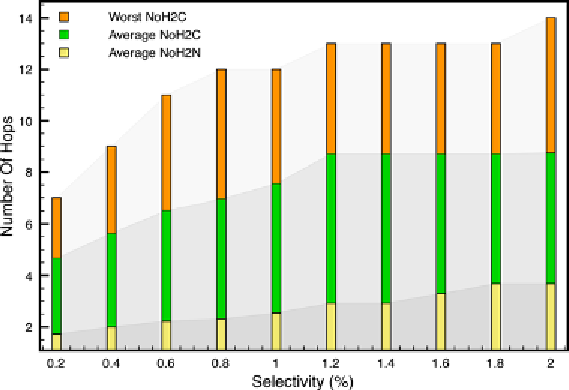
Figure 23. The number of SHOWTUPLES/SHOWCAT operations
2. the average number of hops needed to reach any leaf node (
Average NoH2C
) containing relevant
data (i.e., not necessarily the deepest one);
3. the average number of hops required to reach any node (
Average NoH2N
) containing relevant data
(i.e., not necessarily a leaf node).
Figure 23shows that the
Worst NoH2C
and the
Average NoH2C
are relatively high, but bounded
respectively by the maximum (16) and the average (10.177) depth of the pre-computed tree. It is worth
noticing that, in real life situation, the user finds out that her/his need has been successfully served by
an inner node of the tree rooted by
z
. Thus, the
Average NoH2N
is more adapted to evaluating the ef-
fectiveness of our approach (
ESRA
). As one can observe, the
Average NoH2N
is quite small given the
number of tuples in the
q
result set. For instance,
NoH2N
= 3.68 is the number of hops the user takes
to reach relevant information within a set of 674 tuples (
η
= 2).Those experimental results validate the
claim of this work, that is to say the
ESRA
algorithm is very efficient (Figure 20) and provides useful
clusters of query results (Figure 21 and Figure 22) and consequently, makes the exploration process
more effective (Figure 23).
4. CONCLUSION
Interactive and exploratory data retrieval are more and more suitable to database systems. Indeed, regu-
lar 'blind' queries often retrieve too many answers. Users then need to spend time sifting and sorting
through this information to find relevant data.
In this chapter, we proposed an efficient and effective algorithm coined Explore-Select-Rearrange
Algorithm (
ESRA
) that uses database SAINTETIQ summaries to quickly provide users with concise,
useful and structured representations of their query results. Given a user query,
ESRA
(i) explores the
summary hierarchy (computed offline using SAINTETIQ) of the whole data stored in the database;