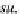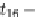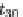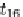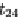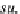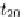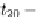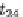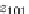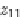Database Reference
In-Depth Information
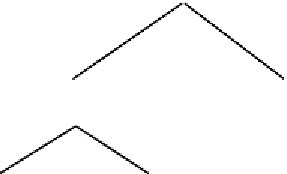
Figure 18. Summary z
1
SHOWCAT option for further expansion). At the end of the exploration of the children of
z
i
, go
ahead and examine
z
i+1
.
For instance, suppose a user is looking for
medium
,
large
as well as
expensive
houses in the
suburb
but issues the broad query
Q
1
(Example 3.1): 'find
medium
or
large
houses in the
suburb
'. The set of
summaries
S
presented to that user is {
z
1
}, where
z
1
is a subtree (Figure 18) in the pre-computed sum-
mary hierarchy shown in Figure 17. In this situation, the user can explore the subtree rooted by
z
1
as
follows to reach relevant tuples: analyze the intent of
z
1
and explore it using SHOWCAT option, analyze
the intent of
z
10
and ignore it, analyze the intent of
z
11
and use SHOWTUPLES option to navigate through
the tuples in
R
z
11
(i.e.,
t
25
-
t
30
) to identify each relevant tuple.
Note that when the set
S
= {
z
} is a singleton, i.e.,
z
is a node of the pre-computed clustering tree, its
exploration is straightforward. Indeed, given a summary of the tree rooted by
z
that the user wishes to
examine more closely (SHOWCAT option), its children are well separated since SAINTETIQ is designed
to discover summaries (clusters) that locally optimize the objective function
U
. Furthermore, the num-
ber of clusters presented to the user, at each time, is small; the highest value is equal to the maximum
width of the pre-computed tree. However, since the summary hierarchy is independent of the query, the
set of starting point answers
S
could be large and consequently dissimilarity between summaries is
susceptible to skew. It occurs when the summary hierarchy is not perfectly adapted to the user query. In
this situation, it is hard for the user to separate the interesting summaries from the uninteresting ones,
thereby leading to potential decision paralysis and wastage of time and effort.
In the next subsection, we propose an original rearranging query results algorithm to tackle this problem.
3.4 Rearranging the Result Set
The problem of discrimination (dissimilarity) between
ESA
's results occurs when these results are scat-
tered over the queried summary hierarchy. This situation is illustrated in Figure 19 (Left), where the set
of summaries
S
= {
z
00
,
z
01
,
z
1000
,
z
101
,
z
11
} is returned by
ESA
as the result of a query
Q
over the summary
hierarchy
H
.
A straightforward way to address this problem would be to, first, execute the SAINTETIQ summa-
rization service (
SEQ
) on the cells populated by records of
tset(Q)
, i.e., the cells covered by summaries