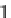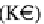Database Reference
In-Depth Information
Figure 15. Fuzzy linguistic partition defined on the attribute Price
3.1.1 A Two-Step Process
SAINTETIQ takes tabular data as input and produces multi-resolution summaries of records through
an online mapping process and a summarization process.
3.1.1.1 Mapping Service
SAINTETIQ system
relies on Zadeh's fuzzy set theory (Zadeh, 1956), and more specifically on linguistic variables (Zadeh,
1975) and fuzzy partitions (Ruspini, 1969), to represent data in a concise form. The fuzzy set theory is
used to translate records in accordance with a Knowledge Base (
KB
) provided by a domain expert or
even an end-user. Basically, the operation replaces the original values of each record in the table by a
set of linguistic labels defined in the
KB
. For instance, with a linguistic variable on the attribute Price
(Figure 15), a value
t
.Price = 95000€ is mapped to {0.3/
cheap
, 0.7/
reasonable
} where 0.7 is a member-
ship grade that tells how well the label
reasonable
describes the value 95000. Extending this mapping
to all the attributes of a relation could be seen as mapping the records to a grid-based multidimensional
space. The grid is provided by the
KB
and corresponds to the user's perception of the domain.
Thus, tuples of Table 7 are mapped into two distinct grid-cells denoted by
c
1
and
c
2
in Table 8.
old
is
a fuzzy label a priori provided by the
KB
on attribute Age and it perfectly matches (with degree 1) range
[19, 24] of raw values. Besides, 0.3/
cheap
says that
cheap
fits the data only with a small degree (0.3).
The degree is computed as the maximum of membership grades of tuple values to cheap in
c
1
.
Flexibility in the vocabulary definition of
KB
permits to express any single value with more than one
fuzzy descriptor and avoid threshold effect due to a smooth transition between two descriptors. Besides,
KB
leads to the point where tuples become indistinguishable and then are grouped into grid-cells such
that there are finally many more records than cells. Every new (coarser) tuple stores a record count and
attribute-dependant measures (min, max, mean, standard deviation, etc.). It is then called a summary.
3.1.1.2 Summarization Service
The summarization service (
SEQ
) is the second and the most sophisticated step of the SAINTETIQ
system. It takes grid-cells as input and outputs a collection of summaries hierarchically arranged from
the most generalized one (the root) to the most specialized ones (the leaves). Summaries are clusters of
grid-cells, defining hyperrectangles in the multidimensional space. In the basic process, leaves are grid-
cells themselves and the clustering task is performed on
L
cells rather than
n
tuples (
L << n
).
From the mapping step, cells are introduced continuously in the hierarchy with a top-down approach
inspired of D.H. Fisher's CobWeb, a conceptual clustering algorithm (Fisher, 1987). Then, they are in-
corporated into best fitting nodes descending the tree. Three more operators could be apply, depending
on partition's score, that are
create
,
merge
and
split
nodes. They allow developing the tree and updating
its current state. Figure 16 represents the summary hierarchy built from the cells c1 and c2 of Table 8.