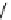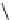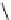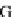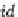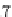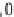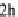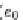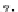Database Reference
In-Depth Information
Figure 7. An example of a personalization graph (cf. (Koutrika & Ioannidis, 2005))
tuples of
R
satisfying
QP
1
P
2
; if the result is empty, pick the tuples satisfying
Q
¬
¿
¿
P
1
P
2
; if the result is
¬
empty, pick the tuples satisfying
Q
P
1
P
2
. In other words,
Q
is a 'hard' constraint, whereas
P
1
and
P
2
are preferences or 'soft' constraints. Since then extensive investigation has been conducted, and two
main types of approaches have been distinguished in the literature to deal with the user's preferences,
namely, quantitative and qualitative (Chomicki, 2003).
2.3.1.1 Quantitative Preferences
The quantitative approach expresses preferences using scoring functions, which associate a numeric score
with every tuple of the query, e.g. 'I like tuple
t
with score 0.5'. Then tuple
t
1
is preferred over tuple
t
2
if and only if the score of
t
1
is higher than the score of
t
2
. Agrawal et al. (Agrawal & Wimmers, 2000)
provided a framework for expressing and combining such kinds of preference functions.
Recently, Koutrika et al. (Koutrika & Ioannidis, 2005) presented a richer preference model which
can associate degrees of interest (like scores) with preferences over a database schema. Thus, from this
aspect, it seems to follow a quantitative approach. These preferences are all kept in a user profile. A user
profile is viewed as a directed graph
ζ ϑ
,E
(called Personalization Graph), where
J
is the set of
nodes and
E
the set of edges. Nodes in
J
are (a) relation nodes, one for each relation in the schema, (b)
attribute nodes, one for each attribute of each relation in the schema, and (c) value nodes, one for each
value that is of any interest to a particular user. Edges in
E
are (a) selection edges, representing a pos-
sible selection condition from an attribute to a value node, and (b) join edges, representing a join between
attribute nodes. An example of a user profile is given in Figure 7. It indicates among others a preference
for movies of duration around 2h and a big concern about the genre of a movie. The first value between
brackets indicates the preference for the presence of the associated value, the second indicates the pref-
erence for the absence of the associated value. The function
e
stands for an elastic preference. Further-
more, the authors proposed a query personalization algorithm which exploits the user profile to dy-
namically enrich (personalize) user queries prior to their execution. For example, the personalization of
a user query can add selection conditions to a query, meaning that the user obtains a subset of the answer
to the initial query. In general, it is expected that this subset contains the most interesting tuples (with
respect to the user preferences) of the global answer.
Koutrika et al's approach (Koutrika & Ioannidis, 2005) provides one of the first solutions towards
modelling of user preferences in Database systems in the form of a structured profile. In (Kostadinov,
Bouzeghoub & Lopes, 2007), the authors elaborated a taxonomy of the most important knowledge