Database Reference
In-Depth Information
TABLE 3.1:
Accuracy results for WebKB. CC algorithms
outperformed their CO counterparts significantly, and LR versions
outperformed NB versions significantly. The differences between
ICA-NB and GS-NB, and the differences between ICA-LR and GS-LR,
are not statistically significant. Both LBP and MF outperformed
ICA-LR and GS-LR significantly.
Algorithm
4-fold
0
.
7030
CO-NB
0
.
7215
ICA-NB
GS-NB
0
.
7234
CO-LR
0
.
7734
ICA-LR
0
.
7956
GS-LR
0
.
7969
LBP
0
.
8446
MF
0
.
8446
performed t-test (paired where applicable, and Welch t-test otherwise) to test
statistical significance between results. Here are the main results:
1. Do CC algorithms improve over CO counterparts?
In all three datasets, CC algorithms outperformed their CO counter-
parts, in all evaluation strategies (SS, RS and M). The performance
differences were significant for all comparisons except for the NB (M)
results for CiteSeer.
2. Does the choice of the base classifier affect the results of the CC algo-
rithms?
We observed a similar trend for the comparison between NB and LR. LR
(and the CC algorithms that used LR as a base classifier) outperformed
NB versions in all datasets, and the difference was statistically significant
for both WebKB and Cora.
3. Is there any CC algorithm that dominates the other?
The results for comparing CC algorithms are less clear. In the NB
partition, the difference between ICA-NB and GS-NB was not significant
for WebKB, ICA-NB outperformed GS-NB significantly for Cora using
SS and M, and GS-NB outperformed ICA-NB for CiteSeer SS. Thus,
there was no clear winner between ICA-NB and GS-NB in terms of
performance. In the LR portion, again the differences between ICA-
LR and GS-LR were not significant for all datasets. As for LBP and
MF, they outperformed ICA-LR and GS-LR most of the time, but the
differences were not significant for Cora and CiteSeer.
4. How do SS results and RS results compare?














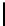


















Search WWH ::

Custom Search