Database Reference
In-Depth Information
What
is
the
capital
city
of
Japan
0
WP
VBZ
DT
NN
NN
IN
NNP
1
WHNP
VP
NP
NP
2
3
PP
4
NP
5
SQ
SBARQ
6
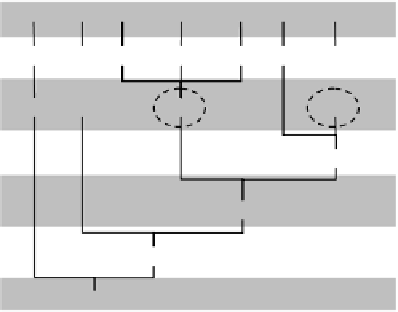
FIGURE 10.5
: Stanford Parser output example.
i
1
2
3
4
5
6
7
y
i
0
0
0
1
1
2
2
x
i
What
is
the
capital
city
of
Japan
Features for
x
i
s
1 WP,1 VBZ,1 DT,1 NN,1 NN,1 IN,1 NNP,1
2 WHNP,1 VP,1 NP,1
NP
,1 NP,1 Null,1
NP,2
3 Null,1 Null,1 Null,1 Null,1 Null,1 PP,1 PP,1
4 Null,1 Null,1 NP,1 NP,1 NP,1 NP,1 NP,1
5 Null,1 SQ,1 SQ,1 SQ,1 SQ,1 SQ,1 SQ,1
6 SBARQ SBARQSBARQSBARQSBARQSBARQSBARQ
↓
FIGURE 10.6
: A multi-resolution tabular view of the question parse
showing
tag
and
num
attributes in each cell.
capital city
is the informer
span with
y
=1.
interested in associating a binary label (informer token or not) with the leaf
nodes of the parse tree. It is tempting to cast this as a structured prediction
problem where the graph is the parse tree itself, and the edges of the parse
tree express Markov dependencies. A straightforward implementation of this
approach may limit the exploitation of long-range features observable from
the parse tree. For example, we may observe from training data that informer
spans occur more often near the beginning of the question, but are rarely the
first word. In other words, there is a distribution over token positions where
the informer span occurs. Also consider the information latent in the parse
tree at multiple levels of resolution. For example, in Figure 10.5, to label
city
as part of the informer span, it may help us more to know that the next chunk
of Japan
has POS “PP” at level 3, than to know that the next token
of
has
POS “IN” at level 1.
To exploit these valuable clues, we will first express the question parse tree











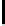



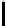
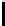












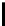





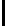





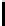


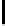





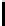






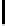

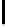
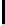





Search WWH ::

Custom Search