Database Reference
In-Depth Information
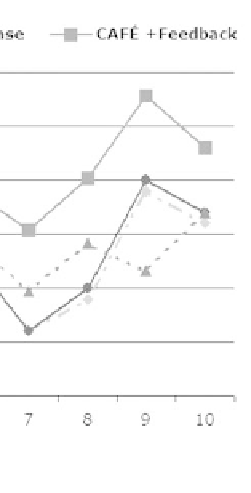
FIGURE 9.2
: Performance of
CAFE
and Indri across chunks.
of how well a system can generalize from user feedback, rather than using
traditional IR measures like recall and precision which give an incomplete
picture of improvement when using feedback.
Since documents were processed chunk by chunk, it would be interesting
to see how the performance of systems improves over time. Figures 9.2
shows the performance trends for both the systems across chunks. While the
performance with and without feedback on the first few chunks is expected
to be close, for subsequent chunks, the performance curve with feedback
enabled rises above the one with the no-feedback setting. The performance
trends are not consistent across all chunks because on-topic documents are
not uniformly distributed over all the chunks, making some queries 'easier'
than others in certain chunks. Moreover, since Indri uses pseudo-relevance
feedback while our system uses feedback based on actual relevance judgments,
the improvement in case of Indri is less dramatic than that of our system.
When PNDCU is measured with
β
= 0 (no redundancy allowed),
enabling novelty detection and anti-redundant ranking with feedback shows
an improvement of 4.3% compared to when only feedback is enabled. Of
course, a smaller improvement (2.8%) is natural when using
β
=0
.
1sincethe
user now prefers to see repetition in the ranked passages.
In a realistic setting, users may sometimes want to see the same information
from multiple sources, as an indicator of its importance or reliability. In such
a case, they might choose to turn off novelty detection and anti-redundant









Search WWH ::

Custom Search