Database Reference
In-Depth Information
Mixed
Cluster1
Cluster2
1
1
0.8
0.8
0.6
0.6
0.4
0.4
0.2
0.2
0
0
−0.2
−0.2
−0.4
−0.4
−0.6
−0.6
−0.8
−0.8
−1
−1
−1
−0.5
0
0.5
1
−1
−0.5
0
0.5
1
(a)
(b)
The small-mix dataset.
A clustering of small-mix.
FIGURE 6.4 (SEE
COLOR INSERT
FOLLOWING PAGE 130.)
:
Small-mix dataset and its clustering by
soft-moVMF
.
though not surprising, since small-mix is a dataset with well-separated clus-
ters. Further testimony to
soft-moVMF
's performance is served by Table 6.2,
which shows the discrepancy between true and estimated parameters for the
small-mix collection.
TABLE 6.2:
True and estimated parameters for small-mix
using
soft-moVMF
.
Cluster
μ
μ
κ
κ
α
α
1
(-0.251, -0.968)
(-0.279, -0.960)
4
3.78
0.48
0.46
2
(0.399, 0.917)
(0.370, 0.929)
4
3.53
0.52
0.54
α
represent the
estimated parameters. We can see that even in the presence of a limited
number of data points in the small-mix dataset (50 points), the estimated
parameters approximate the true parameters quite well.
Before moving onto real datasets let us briefly look at the behavior of the
algorithms on the larger dataset big-mix. On calculating MI as described
previously we found that all the algorithms performed similarly with MI values
close to one. We attribute this good performance of all the algorithms to the
availability of a sucient number of data points and similar sized clusters.
For reference
Table 6.3
offers numerical evidence about the performance of
soft-moVMF
on the big-mix dataset.
In the table
μ, κ, α
represent the true parameters and
μ
,
κ
,





































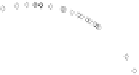










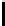
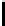




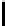



Search WWH ::

Custom Search