Database Reference
In-Depth Information
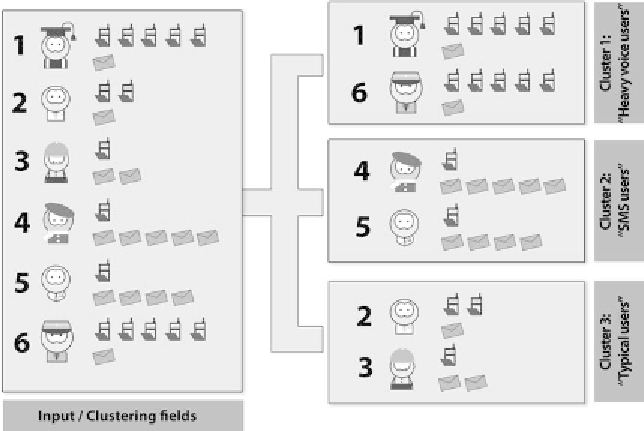
Figure 2.11
Graphical representation of clustering.
records with similar input data patterns, hence similar behavioral profiles, to the
same cluster.
Nowadays, various clustering algorithms are available, which differ in their
approach for assessing the similarity of records and in the criteria they use
to determine the final number of clusters. The whole clustering ''revolution''
started with a simple and intuitive distance measure, still used by some clustering
algorithms today, called the Euclidean distance. The Euclidean distance of two
records or objects is a dissimilarity measure calculated as the square root of the sum
of the squared differences between the values of the examined attributes/fields. In
our example the Euclidean distance between customers 1 and 6 would be:
√
[(Customer 1 voice usage
Customer 6 voice usage)
2
−
Customer 6 SMS usage)
2
]
+
(Customer 1 SMS usage
−
=
24
This value denotes the disparity of customers 1 and 6 and is represented in
the respective scatterplot by the length of the straight line that connects points
1 and 6. The Euclidean distances for all pairs of customers are summarized in
Table 2.7.
A traditional clustering algorithm, named agglomerative or hierarchical clus-
tering, works by evaluating the Euclidean distances between all pairs of records,
literally the length of their connecting lines, and begins to group them accordingly
Search WWH ::

Custom Search