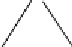Information Technology Reference
In-Depth Information
Finally, the tic-tac-toe player was able to look ahead and know the states that
would result from each of its possible moves. To do this, it had to have a model
of the game that allowed it to “think about” how its environment would change
in response to moves that it might never make. Many problems are like this, but
in others even a short-term model of the effects of actions are lack.
Reinforcement learning can be applied in either case. No model is required, but
models can easily be used if they are available or can be learned.
10.6 Q-Learning
One of the most important breakthroughs in reinforcement learning was the
development of an off-policy TD control algorithm known as Q-learning.
Q-learning is a reinforcement learning technique that works by learning an
action-value function that gives the expected utility of taking a given action in a
given state and following a fixed policy thereafter. A strength with Q-learning is
that it is able to compare the expected utility of the available actions without
requiring a model of the environment.
The core of the algorithm is a simple value iteration update. For each state,
s
,
from the state set
, we can calculate
an update to its expected discounted reward with the following expression:
S
, and for each action,
a
, from the action set
A
(10.15)
Q
(
s
,
a
)
←
(
−
c
)
×
Q
(
s
,
a
)
+
c
×
[
r
+
γ
MAX
Q
(
s
,
a
)
−
Q
(
s
,
a
)]
t
t
t
t
t
+
1
t
+
1
t
t
a
where
r
t
is an observed real reward at time
t,
c
are the learning rates such that
0
±
±
1, and
ȳ
is the discount factor such that 0
±ȳ
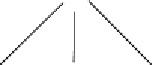
< 1. Figure 10.7 illustrates
the learning trace of V* and Q*.
c
s
s, a
r
max
s
'
a
r
max
a
'
s
'
b)
a)
Fig. 10.7. a)V* and b)Q* Learning Trace