Information Technology Reference
In-Depth Information
immediate reward under the new action policy. The learning process is as
follows:
*
*
*
v
→
π
→
v
→
π
→
→
v
→
π
→
v
?
0
1
1
2
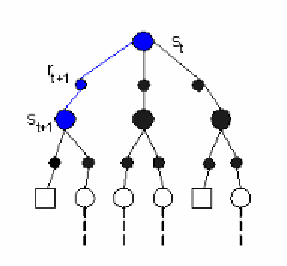
Until the value function and the policy reach the stable value. In TD learning, the
computation of value function is shown in Figure 10.5.
Fig. 10.5. Temporal-difference Learning Method
To illustrate the general idea of reinforcement learning and contrast it with
other approaches, we consider the familiar child's game of tic-tac-toe. Two
players take turns playing on a three-by-three board. One player plays
◇
s and
the other Os until one player wins by placing three marks in a row, horizontally,
vertically, or diagonally.
If the board fills up with neither player getting three in a row, the game is a
draw. Because a skilled player can play so as never to lose, let us assume that we
are playing against an imperfect player, one whose play is sometimes incorrect
and allows us to win. For the moment, in fact, let us consider draws and losses to
be equally bad for us. How might we construct a player that will find the
imperfections in its opponent's play and learn to maximize its chances of
winning?
An evolutionary approach to this problem would directly search the space of
possible policies for one with a high probability of winning against the opponent.
Here, a policy is a rule that tells the player what move to make for every state of
the game--every possible configuration of
◇
s and Os on the three-by-three board.
For each policy considered, an estimate of its winning probability would be