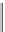Database Reference
In-Depth Information
T(FID,M)
VDFID
M
S(FID,SSN,N)
VDFID
SSN
N
V
1
351
1
X
1
351
185
Smith
V
2
351
2
X
2
351
785
Smith
W
1
352
1
Y
1
352
185
Brown
W
2
352
2
Y
2
352
186
Brown
W
3
352
3
W
4
352
4
Figure 2.9:
A U-database representing the census data in
Figure 2.1
. It consists of two vertical partitions:
the census relation is recovered by a natural join,
R(FID, SSN, N, M)
T(FID, M)
.
The probability distribution function for all atomic events is stored in a separate table
W(V,D,P)
(not
shown).
=
S(FID, SSN, N)
xx
Q
V
1
V
2
V
3
V
4
X
1
Y
1
-
-
a
1
a
1
X
1
Y
2
-
-
a
1
a
1
X
1
Y
1
X
2
Y
3
a
1
a
2
X
2
Y
3
X
1
Y
1
a
2
a
1
X
2
Y
3
-
-
a
2
a
2
Each “
” means NULL. For example, the first tuple
(a
1
,a
1
)
is annotated with
X
1
Y
1
; the second tuple
is also
(a
1
,a
1
)
and is annotated with
X
1
Y
2
, which means that the lineage of
(a
1
,a
1
)
is
X
1
Y
1
∨
X
1
Y
2
,
the same as in
Example 2.14
. The third tuple is
(a
1
,a
2
)
and is annotated with
X
1
Y
1
X
2
Y
3
, etc.
−
Example 2.22
Consider our original census table, in
Example 2.1
,
R(FID, SSN, N, M)
, which has
two uncertain attributes: SSN and M (marital status). Since these two attributes are independent,
a U-database representation of
R
can consist of the two vertical partitions
S
and
T
shown in
Figure 2.9
.The original table
R
is recovered as a natural join (on attribute
FID
) of the two partitions:
R
=
S
T
.
U-databases have two important properties, which make them an attractive representation
formalism. The first is that they form a complete representation system:
Proposition 2.23
U-databases are a complete representation system.
Proof.
Recall that in the proof of
Theorem 2.12
, where we showed that pc-tables form a complete
representation system, where a possible tuple
t
is annotated with
t
=
i
:
t
∈
R
j
(X
=
i)
.Sucha
pc-table can be converted into a U-database by making several copies of the tuple
t
, each annotated
with an atomic formula
X
=
i
. Thus, the U-database needs a single pair
(V , D)
of distinguished
attributes.