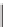Database Reference
In-Depth Information
Query
Syntactic
Membership in
UCQ(
C
)
, where
is
C
OBDD FBDD dDNNF
¬
properties
RO
P
hierarchical;
non-repeating
Q
U
=
R(x
1
), S(x
1
,y
1
)
∨
T(x
2
), S(x
2
,y
2
)
yes
yes
yes
yes
yes
Q
J
=
R(x
1
), S(x
1
,y
1
)
∧
T(x
2
), S(x
2
,y
2
)
no
yes
yes
yes
yes
inversion-free
has inversion;
all lattice points
have separators
Q
V
=
R(x
1
), S(x
1
,y
1
)
∨
S(x
2
,y
2
), T (y
2
)
∨
R(x
3
), T (y
3
)
no
no
yes
yes
yes
lattice point 0
has no separator;
is erasable
Q
W
(
Figure 4.1
)
no
no
no
yes
yes
lattice point 0
has no separator;
has
μ
=
0;
non-erasable
Q
9
(
Figure 5.3
)
no
no
no
no?
yes
lattice point 0
has no separator;
and has
μ
=
0
H
1
=
R(x
1
), S(x
1
,y
1
)
∨
S(x
2
,y
2
), T (y
2
)
no
∗
no
no
no
no
Figure 5.5:
Queries used to separate the classes in
Figure 5.4
. All queries are hierarchical and have
some additional syntactic properties indicated in the table. 0 denotes the minimal element of the query's
CNF-lattice;
μ
its Möbius function.
no?
means conjectured.
no
∗
means “assuming
P
=
#
P
”.
5.5
DISCUSSION
In summary, intensional query evaluation first constructs the lineage
of a query, then computes the
probability
P ()
of this propositional formula. The advantage of this approach lies in its generality:
every query on any database can be evaluated this way, on any pc-database. The disadvantage is that it
is impossible to guarantee scalability because computing
P ()
is #P-hard, in general. Applying the
heuristics discussed in
Section 5.1
may work very well in some cases, but it may lead to exponential
running times in other cases: thus, the query processor is not predictable.