Information Technology Reference
In-Depth Information
be temporally predicted using variable block size motion-compensated prediction
with multiple reference frames. The macroblock type signals the partitioning of a
macroblock into blocks of 16x16, 16x8, 8x16, or 8x8 luma samples. When a mac-
roblock type specifies partitioning into four 8x8 blocks, each of these so-called
sub-macroblocks can be further split into 8x4, 4x8, or 4x4 blocks, which is
indicated through the sub-macroblock type. For P-slices, one motion vector is
transmitted for each block. In addition, the employed reference picture can be in-
dependently chosen for each 16x16, 16x8, or 8x16 macroblock partition or 8x8
submacroblock. It is signalled via a reference index parameter, which is an index
into a list of reference pictures that is replicated at the decoder [8, 10].
M
A
B C D E
F G H
M
A
B C D E
F G H
M
A
B C D E
F G H
I
J
K
L
I
J
K
L
I
J
K
L
Mean
([A..D],
[I..L] )
…
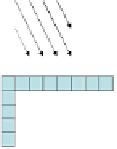
0 (vertical)
1 (horizontal)
2 (DC)
M
A
B C D E
F G H
M
A
B C D E
F G H
M
A
B C D E
F G H
I
J
K
L
I
J
K
L
I
J
K
L
0 (vertical)
1 (horizontal)
3 (diagonal down-left)
4 (diagonal down-right)
5 (vertical-right)
M
A
B C D E
F G H
M
A
B C D E
F G H
M
A
B C D E
F G H
Mean of
+
I
J
K
L
I
J
K
L
I
J
K
L
6 (horizontal-down)
7 (vertical-left)
8 (horizontal-up)
2 (DC)
3 (plane)
(a)
(b)
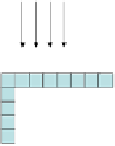
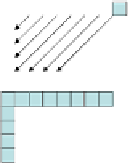
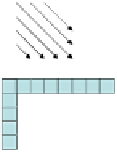
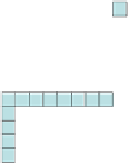
Fig. 2
Directional intra-prediction modes. (a) 4x4 prediction modes. (b) 16x16 prediction
modes. [10].
In B-slices, two distinct reference picture lists are utilized, and for each 16x16,
16x8, 8x16 macroblock partition or 8x8 sub-macroblock, the prediction method can
be selected between list 0, list 1, or bi-prediction. While list 0 and list 1 prediction
refer to unidirectional prediction using a reference picture of reference picture list 0
or 1, respectively, in the bi-predictive mode, the prediction signal is formed by a
weighted sum of a list 0 and list 1 prediction signal. In addition, special modes such
as direct modes in B-slices and skip modes in P- and B-slices are provided, in
which motion vectors and reference indexes are derived from previously transmit-
ted information [8]. To reduce the blocking artefacts introduced by the standard's
block-based transform and prediction operations, an adaptive deblocking filter is
applied in the motion-compensated prediction loop [11]. This filter is only effec-
tively turned on for higher values of the quantization parameter QP [11].
After spatial or temporal prediction, the resulting prediction error is trans-
formed using an approximation of the discrete cosine transform (DCT), in some
cases followed by an Hadamard transform on the DC DCT coefficients (Intra
16x16 prediction mode, chroma coefficient blocks). In the initial version of the
standard, a 4x4 DCT kernel was used exclusively. Later, during the standardiza-
tion of FRExt, an 8x8 transform kernel was added, which typically provides