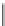Database Reference
In-Depth Information
LID
hospitalization registers
causes-of-death registers Probability
Id
Name
Disease
Id
Name
Age
l
1
a
1
John H. Smith
Leukemia
b
1
Johnny Smith
32
0
.
3
0
.
3
l
2
a
1
John H. Smith
Leukemia
b
2
John Smith
35
l
3
a
1
John H. Smith
Leukemia
b
3
J. Smith
61
0
.
4
l
4
a
2
Johnson R. Smith Lung cancer
b
3
J. Smith
61
0
.
2
8
Table 2.4
Record linkages between the hospitalization registers and the causes-of-death registers.
l
5
a
2
Johnson R. Smith Lung cancer
b
4
J. R. Smith
45
0
.
If we consider all possible worlds corresponding to the set of linkages shown in
Table 2.4 (the concept of possible world on probabilistic linkages will be defined in
Definition 2.20), then the probability that
Johnson R. Smith
is younger than
John
H. Smith
is
0
.
4
, while that probability that
John H. Smith
is younger than
Johnson
R. Smith
is
0
6
. Clearly, between the two patient,
John H. Smith
died at a younger
age than
Johnson R. Smith
with higher probability. How to compute this probability
will be discussed in Chapter 7.
In this example, we can consider each linked pair of records as an uncertain
instance and each record as an uncertain object. Two uncertain objects from differ-
ent data sets may share zero or one instance. Therefore, the uncertain objects may
not be independent. We develop the probabilistic linkage model to describe such
uncertain data.
.
be a set of real-world entities. We consider two tables
A
and
B
which
describe subsets
Let
E
E
,E
⊆E
E
of entities in
. Each entity is described by at most one
A
B
tuple in each table. In general,
E
E
A
and
B
may not be identical. Tables
A
and
B
may
have different schemas as well.
Definition 2.19 (Probabilistic linkage).
Consider two tables
A
and
B
, each describ-
ing a subset of entities in
E
,a
linkage function
L
:
A
×
B
→
[
0
,
1
]
gives a score
L
(
t
A
,
t
B
)
for a pair of tuples
t
A
∈
A
and
t
B
∈
B
to measure the likelihood that
t
A
and
t
B
describe the same entity in
E
. A pair of tuples
l
=(
t
A
,
t
B
)
is called a
proba-
bilistic record linkage
(or
linkage
for short) if
L
(
l
)
>
0.
Pr
(
l
)=
L
(
t
A
,
t
B
)
is the
membership probability
of
l
.
Given a linkage
l
=(
t
A
,
t
B
)
, the larger the membership probability
Pr
(
l
)
, the more
likely the two tuples
t
A
and
t
B
describe the same entity. A tuple
t
A
A
may participate
in zero, one or multiple linkages. The number of linkages that
t
A
participates in is
called the
degree
of
t
A
, denoted by
d
∈
(
t
A
)
. Symmetrically, we can define the degree
of a tuple
t
B
∈
B
.
For a tuple
t
A
∈
A
, let
l
1
=(
t
A
,
t
B
1
)
,···,
l
d
(
t
A
)
=(
t
A
,
t
B
d
(
t
A
)
)
be the linkages that
t
A
participates in. For each tuple
t
A
∈
A
, we can write a
mutual exclusion rule
R
t
A
=
which indicates that at most one linkage can hold based on
the assumption that each entity can be described by at most one tuple in each table.
Pr
l
1
⊕···⊕
l
d
(
t
A
)
d
(
t
A
)
is the probability that
t
A
is matched by some tuples in
B
. Since
the linkage function is normalized,
Pr
(
t
A
)=
∑
Pr
(
l
i
)
i
=
1
(
t
A
)
≤
1. We denote by
R
A
=
{
R
t
A
|
t
A
∈
A
}
the