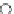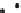Database Reference
In-Depth Information
B
B
C
A
C
A
Fig. 2.2
Non-monotonicity of size-
k
most typical
Fig. 2.3
Medians, means and typical ob-
jects.
group.
10
0.4
0.3
8
b
0.2
6
a
c
0.1
4
0
ac
b
2
-0.1
T(o,white)
0
-0.2
0
2
4
6
8
10
12
X
Location of the data point
(a) A set of points.
(b) Representative typicality.
Fig. 2.4
The answer to a top-2 representative typicality query on a set of points.
A
i
l
of interest, a predicate
P
and a positive integer
k
,a
top-
k
representative typicality query
returns
k
instances
o
1
,...,
Given an uncertain object
O
on attributes
A
i
1
,...,
o
k
from the set of instances in
O
satisfying predicate
P
, such that
o
1
is the
instance having the largest simple typicality, and, for
i
>
1,
o
i
=
arg
max
o
∈
O
−{
o
1
,...,
o
i
−
1
}
RT
(
o
,{
o
1
,...,
o
i
−
1
},
O
)
.
The representative typicality values are computed on attributes
A
i
1
,...,
A
i
l
.
Example 2.7 (Top-k representative typicality queries). Consider the set of points in
Figure 2.4(a) and a top-
2
representative typicality query on attribute X with predi-
cate COLOR
white.
We project the white points to attribute X and plot the simple typicality scores of
the white points, as shown in Figure 2.4(b). Points a and c have the highest simple
typicality scores. However, if we only report a and c, then the dense region around
a is reported twice, but the dense region around b is missed. A top-
2
representative
typicality query will return a and b as the answer.
=