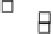Database Reference
In-Depth Information
4000
4000
Exact+DFS
Sampling+DFS
HP-Tree construction
Approximation+P*
Exact+DFS
Sampling+DFS
HP-Tree construction
Approximation+P*
3500
3500
3000
3000
2500
2500
2000
2000
1500
1500
1000
1000
500
500
0
0
6104
21047
175812
6104
21047
175812
Number of nodes
Number of nodes
(a) Normal distribution.
(b) Normal distribution with noise.
Fig. 8.12
Scalability.
Clearly, the P* search is more efficient than the depth first search method thanks
to the heuristic path evaluation during the search. Among the three types of heuristic
estimates, stochastic estimates are the most effective, because they use the weight
probability distribution of the unexplored paths to guide the search. The HP-tree
construction takes 25 seconds on this data set.
The memory usage for different algorithms is shown in Figure 8.10. The memory
requirement in the exact probability calculation method with DFS increases rapidly
when the weight threshold increases, since longer paths are explored with a larger
weight threshold. However, the memory usage in P* search with the bucket approx-
imation probability calculation is stable, because the space used for an HP-tree does
not depend on the weight threshold.
8.4.3 Approximation Quality and Scalability
Using data set
OL
, we test the approximation quality of the sampling algorithm and
the bucket approximation algorithm. In the same parameter setting as in Figure 8.8,
the precision and the recall of all queries are computed. Since they are all 100%, we
omit the figures here.
The average approximation error of the
l
-weight probability computed in the
two algorithms is shown in Figure 8.11. For any path
P
, the approximation error is
defined as
|
F
P
(
l
)
−
F
P
(
l
)
|
, where
F
P
(
l
)
and
F
P
(
l
)
are the approximate and exact
l
-weight
F
P
(
l
)
probabilities of
P
, respectively.
The error rate of the sampling method is always lower than 3%, and is very close
to 0 when a set of 500 samples are used (Figure 8.11(a)). The average error rate of
the bucket approximation method decreases from 4
.
31% to 0
.
1% when the bucket
parameter
t
increases from 10 to 50 (Figure 8.11(b)).
Figure 8.12 shows the scalability of the three algorithms on the five real road
network data sets. Figure 8.12(a) shows the results for weights following the Normal
distribution. Figure 8.12(b) is the results on the data with the Normal distribution
and 10% noise. That is, 10% of the edges have a sample drawn from the uniform