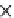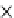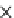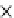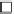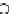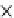Database Reference
In-Depth Information
Query without index
PRist+ construction
Query with PRist+
100
Query without index
PRist+ construction
Query with PRist+
200
80
150
60
100
40
50
20
0
0
200
400
600
800
1000
200
400
600
800
1000
Parameter k
Parameter l
(a) Runtime vs.
k
.
(b) Runtime vs.
l
.
Fig. 5.11
Runtime of top-
(
k
,
l
)
queries.
600
450
Query without index
PRist+ construction
Query with PRist+
Query without index
PRist+ construction
Query with PRist+
400
500
350
400
300
250
300
200
200
150
100
100
50
0
0
0.2
0.4
0.6
0.8
200
400
600
800
1000
Probability threshold
Parameter l
(a) Runtime vs.
p
.
(b) Runtime vs.
l
.
Fig. 5.12
Runtime of top-
(
p
,
l
)
queries.
1800
1600
Query without index
PRist+ construction
Query with PRist+
Query without index
PRist+ construction
Query with PRist+
1600
1400
1400
1200
1200
1000
1000
800
800
600
600
400
400
200
200
0
0
25000
50000
75000 100000 125000
5
10
15
20
25
Number of tuples in the data set
Average number of tuples in a rule
(a) Runtime vs. cardinality.
(b) Runtime vs. rule complexity.
Fig. 5.13
Scalability.
We test the efficiency of the query evaluation methods. Since the query answering
time based on
PRist
and
PRist+
is similar, here we only compare the efficiency
of the query evaluation without index, and the efficiency of the query evaluation
methods based on
PRist+
.PT-
k
queries, top-
queries are
tested in Figures 5.10, 5.11 and 5.12, respectively. The construction time of
PRist+
is also plotted in those figures. There are 10
(
k
,
l
)
queries and top-
(
p
,
l
)
000 tuples and 1000 generation rules.
The number of tuples in a rule follows the normal distribution
N
,
. Clearly, the
query evaluation methods based on
PRist+
have a dramatic advantage over the query
answering methods without the index. Interestingly, even we construct a
PRist+
(
5
,
2
)