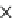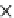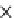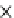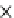Database Reference
In-Depth Information
180
70
RC
RC+AR
Sampling
RC+LR
RC
RC+AR
Sampling
RC+LR
160
60
140
120
50
100
40
80
30
60
20
40
10
20
0
0
0.1
0.3
0.5
0.7
0.9
5
10
15
20
25
Expectation of membership probability
Average number of tuples in a rule
(a) Runtime vs. probability.
(b) Runtime vs. rule complexity.
45
1200
RC
RC+AR
RC+LR
Sampling
RC
Sampling
RC+AR
RC+LR
40
1000
35
30
800
25
600
20
15
400
10
200
5
0
0
200
400
600
800
1000
0.2
0.3
0.4
0.5
0.6
0.7
Parameter k
Probability threshold p
(c) Runtime vs.
k
.
(d) Runtime vs. probability threshold.
Fig. 5.5
Efficiency (same settings as in Figure 5.4).
Since ranking queries are extensively supported by modern database manage-
ment systems, we treat the generation of a ranked list of tuples as a black box, and
test our algorithms on top of the ranked list.
First, to evaluate the efficient top-
k
probability computation techniques, we com-
pare the exact algorithm, the sampling method, and the Poisson approximation
based method for evaluating PT-
k
queries. The experimental results for top-
(
k
,
l
)
(
,
)
queries and top-
queries are similar to the results for PT-
k
queries. Therefore,
we omit the details. For the exact algorithm, we compare three versions: Exact (us-
ing rule-tuple compression and pruning techniques only), Exact+AR (using aggres-
sive reordering), and Exact+LR (using lazy reordering). The sampling method uses
the two improvements described in Section 5.3. Then, we evaluate the online query
answering techniques for PT-
k
queries, top-
p
l
(
k
,
l
)
queries and top-
(
p
,
l
)
queries.
5.6.2.1 Scan Depth
We test the number of tuples scanned by the methods (Figure 5.4). We count the
number of distinct tuples read by the exact algorithm and the
sample length
as the
average number of tuples read by the sampling algorithm to generate a sample unit.
For reference, we also plot the number of tuples in the answer set, i.e., the tuples sat-
isfying the probability threshold top-
k
queries, and the number of tuples computed
by the general stopping condition discussed in Section 5.4.
In Figure 5.4(a), when the expected membership probability is high, the tuples
at the beginning of the ranked list likely appear, which reduce the probabilities of