Information Technology Reference
In-Depth Information
2.1 The Data Model
The actual database was modeled as a “Hashed Indexed Sequential Access Method”
(HSAM) mechanism. Each data record was indexed by a unique primary key that is
used to calculate which frame (or bucket) is its home location inside a given fixed-
size file. So for a given file and frame the read and write commands “compiled”
directly to an absolute disk, head and sector address.
Unlike other data models Pick's record structure is not predetermined by a Data
Definition Language. Traditionally a database is created with the required number of
tables, each table having its own peculiar structure. In Pick, one created files as
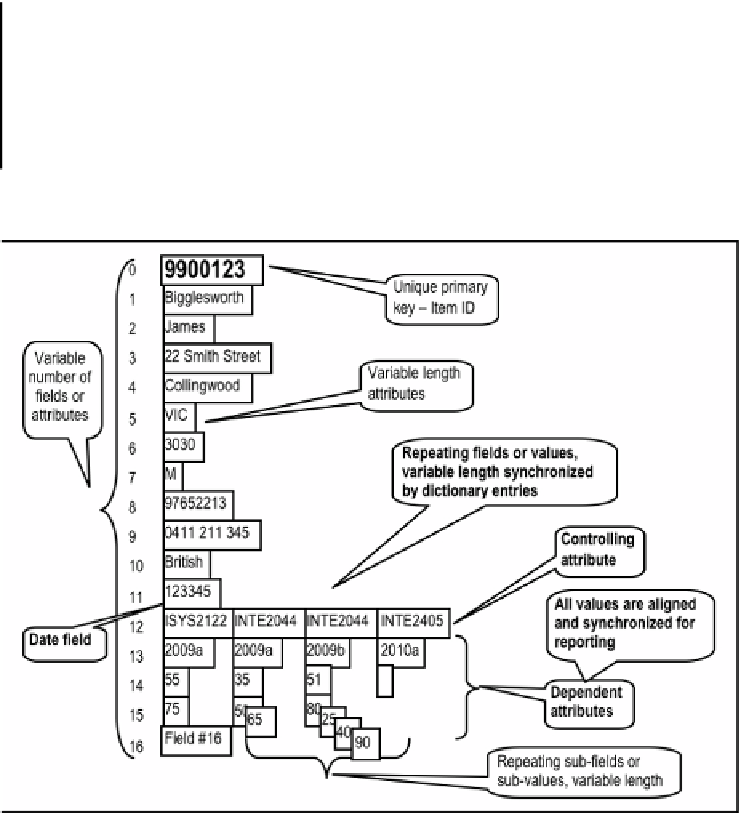
Table 1.
Student Record Layout in Pick
Attribute #
Data
0..11
Traditional fields student ID, names, addresses, sex, phone numbers, DOB
12
Subject code (text)(MV Controlling)(Associated to file Subjects)
13
Semester code enrolled (text)(MV Dependent #12)
14
Result (number)(MV Dependent #12)
15
Assignment result(s)(MV Dependent #12)(Multi-sub-valued- multiple assignment
results allowed)
16…
More attributes
When we look at an actual record, it might be represented like this …
Fig. 1.
Representation of a Student Record










Search WWH ::

Custom Search