Information Technology Reference
In-Depth Information
1. Calculate
{
M
i
,i
∈{
1
···
f
}}
, a randomly partition of
M
and
M
i
the complement
of each element
M
i
.
2. For each
M
i
apply the control and the case selection method (
M
i
σ
).
3. Validate the classifier using Cross-Validation where
M
i
σ
is the training set and
M
i
the test set.
4. Calculate the decision scores: reduction of the case memory, efficiency of the
method, and quality of the solution.
In the first step, the partition is made to identify the test and training sets. In the second
step, the case selection method is applied in order to reduce the case memory. Note
that the case selection method selected should not produce an adverse effect on the
ARS. In order to obtain an initial filtering of the case selection methods, we could
compare them with a control test. In our case, these control methods are: the random
selection process (removing 25,50 or 75 % of the cases from the case memory) and the
none
selection (keeping the original case memory). Therefore, this methodology only
considers acceptable those case selection methods whose results improve or keep the
control methods.
Fig. 1.
Evaluation methodology for case selection algorithms
The third step is a classical Cross-Validation process. Due to the fact that case se-
lection methods are used to improve ARSs, it seems reasonable to include the own
ARS at this step. However, this kind of systems (such as a CBR) could imply high
computationally-cost processes (e.g. similarity or adaptation functions) and the valida-
tion step implies a high number of iterations. Therefore, the custom cross-validation
presented (folder size
f
) executes a case selection method using the training set
M
i
σ
,
the test set
M
i
, and the K-NN as classifier (iterating over
i
,f
). The K-NN
has two components: local and global distances, where the global depends on local.
The local is the distance between the case attributes values, therefore its calculation
depends on the attribute type. In our evaluation there are just two types: numeric and
string of characters, and we call
d
num
the distance between numeric values and
d
string
the distance between string values:
=1
,
···


































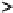


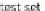

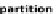


















































Search WWH ::

Custom Search