Information Technology Reference
In-Depth Information
Nevertheless, the variation in the weights only produces the change in the
position of Romanian, what means that, in general, the balanced distribution of
the selected features produces the correct trees for Roman languages. All this
can be seen in Fig. 5.
Fig. 5.
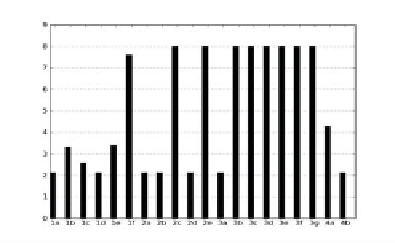
A and B are the trees the system is able to obtain with the 6 latin languages
considered in the example. Right: comparison in the variation in the weights the system
needs to perform to obtain the trees.
However, the system can be forced to find the relevant features to produce
a tree with some constraints. For example, following the classical distribution
of Latin languages we can ask the program to find a tree enforcing Italian and
Romanian together. It is possible to obtain a tree like the one shown in Fig. 6,
with the weights in the range of 2.14-7.98. The traits with the largest weights are
1(f), 2(c), 2(e), 3(b), 3(c), 3(d), 3(e), 3(f), 3(g), among which are features that
closely relate Romanian and Italian, like the number of vowels of their respective
systems (7) and the plural formation. But it is unclear why the system needs
to increase the value of the feature ergativity, that is shared by every Romance
language, except perhaps as a neutral way of reducing the relative weight of all
other features. The graphical representation of the result is found in Fig. 6.
Fig. 6.
Tree obtained by forcing the system to produce together Romanian and Italian.
Plot of the variation of the weights.




Search WWH ::

Custom Search