Information Technology Reference
In-Depth Information
Fig. 2.
Block diagram of the feature weighting process, which maintains an internal
distractors list in order to decide which features present the highest discriminability
Once the distractor list has been updated, it is used to evaluate the discrim-
inability of each feature. To do so each feature will be given a score by adapting
the concept of
peak difference
[9] to our problem. This score is defined by:
score
f
=
averageDissimilarity
f
−
lastTargetDissimilarity
f
(5)
where
score
f
is the score given to feature
f
,
lastTargetDissimilarity
f
is the
dissimilarity amongst the last torso accepted as target and the target model
when this happened. Finally,
averageDissimilarity
f
is the average distractor's
dissimilarity for feature
f
, calculated using the distractor list:
s−
1
d
f
s
averageDissimilarity
f
=
(6)
i
=0
where
s
is the size of the distractors list.
d
f
is the Bhattacharyya distance (Eq.
3) between the histograms of feature
f
for the target and the
i
-distractor on the
list. Finally we will consider the scores previously described to determine the
weight of each feature:
⎧
⎨
0
if
score
f
<
0
.
25
w
f
=
(7)
⎩
0
.
5
w
f
+
score
f
if
score
f
≥
0
.
25
where
w
f
is the weight for feature
f
. After Eq. 7 has been applied, it is necessary
to apply a normalization so that the sum of all the feature-weights is equal to
one. We can notice that equation 7 sets the weight value to zero when the
score of a feature is less than 0.25 (what means that the discriminability of that
feature is poor and therefore it should not be used to compute the dissimilarity
values Eq. 4). Finally, when all the features have a zero score, due to their low
discrimination ability, the weight of the feature with the highest score will be
set to one, leaving the rest of the weights with a zero value.
Finally, we have to modify the dissimilarity equation (Eq. 4) to include the
feature weights just described:
n
weightedDissimilarity
=
w
f
d
f
(8)
f
=1
















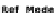















Search WWH ::

Custom Search